 Zatrudnij nas
Zatrudnij nas


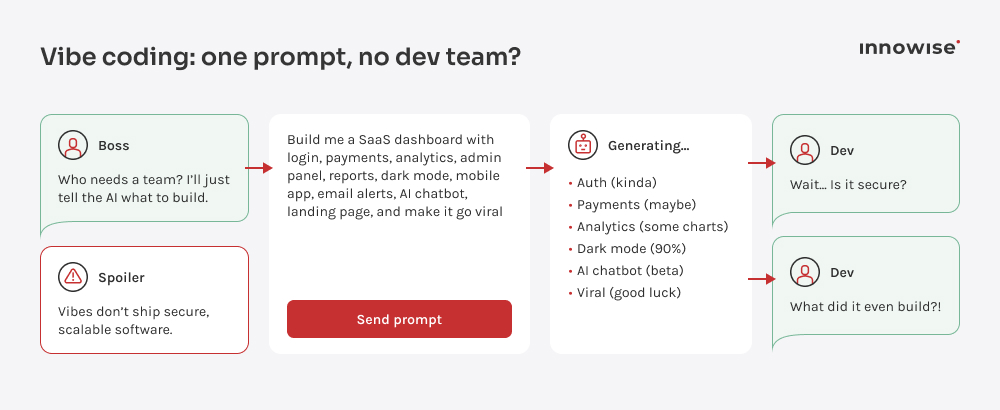
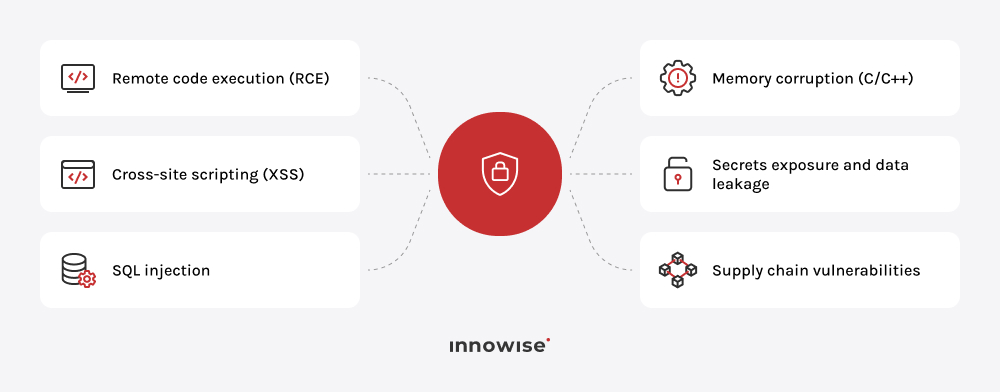
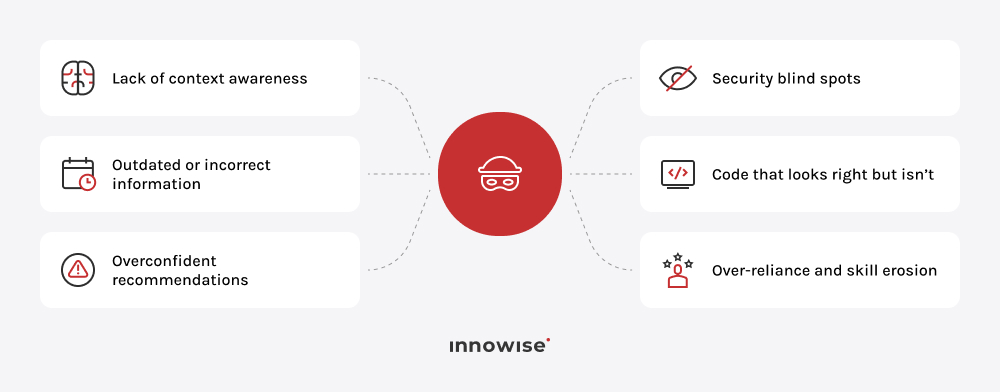










Kodowanie typu „vibe” polega na wykorzystaniu narzędzi opartych na sztucznej inteligencji do szybkiego generowania kodu, często na podstawie podpowiedzi lub instrukcji. Pomaga to przyspieszyć proces tworzenia oprogramowania i obniża barierę wejścia w tę dziedzinę, jednak kod nadal wymaga weryfikacji pod kątem bezpieczeństwa, wydajności i poprawności.














Dziękuję!
Wiadomość została wysłana.
Przetworzymy Twoją prośbę i skontaktujemy się z Tobą tak szybko, jak to możliwe.
