












Dziękuję!
Wiadomość została wysłana.
Przetworzymy Twoją prośbę i skontaktujemy się z Tobą tak szybko, jak to możliwe.
Formularz został pomyślnie przesłany.
Więcej informacji można znaleźć w skrzynce pocztowej.
 Zatrudnij nas
Zatrudnij nas


The Innowise team took ownership of a significant portion of the new product right from the start of our engagement. They have worked very closely with our technical lead to learn the current code base, assist in designing its architecture, and have been involved in making architectural decisions since day one of the project. Over the entire course of this collaboration, we have enjoyed good communication, with frequent daily standup meetings and regularly scheduled sync sessions.


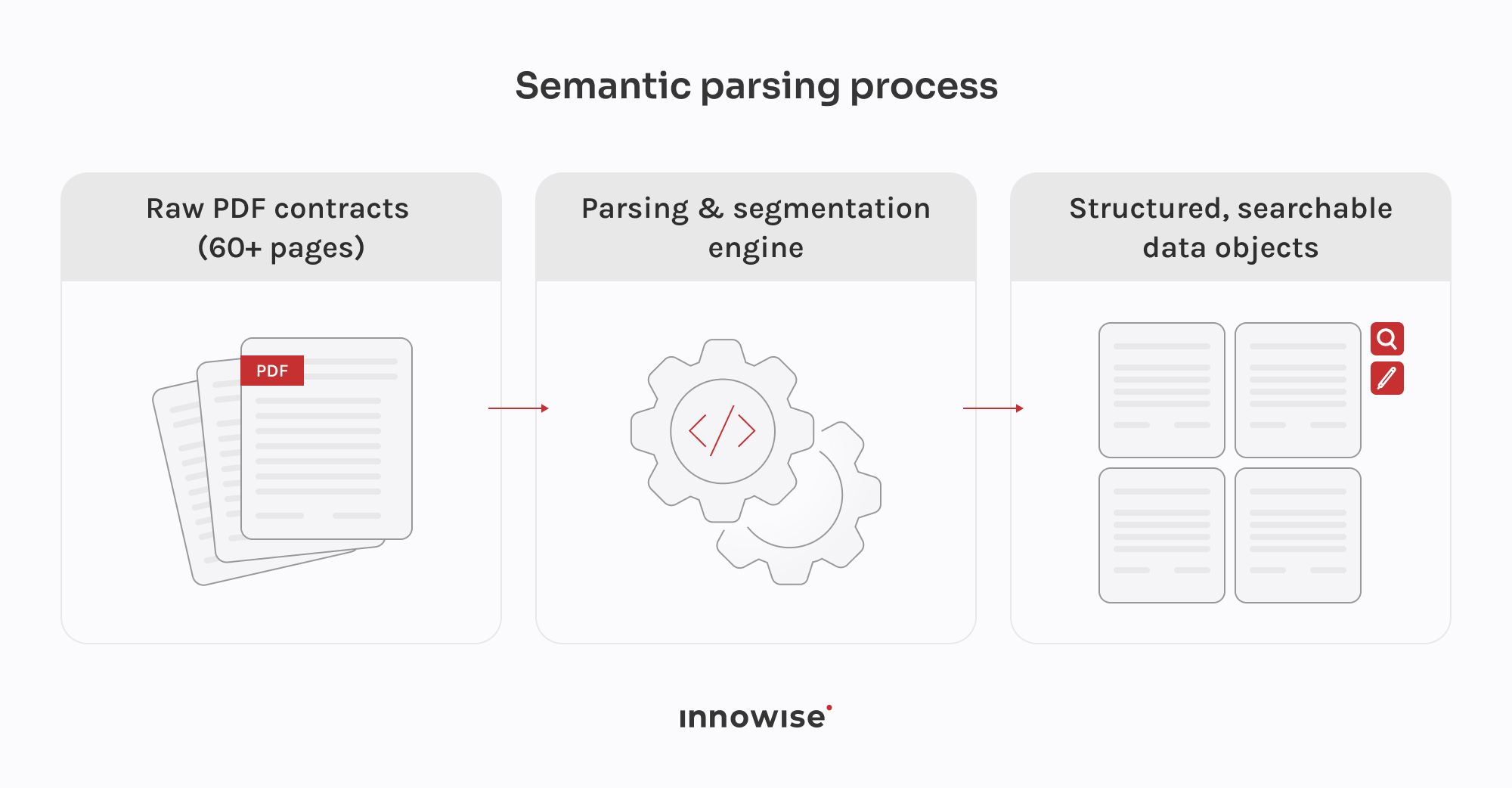
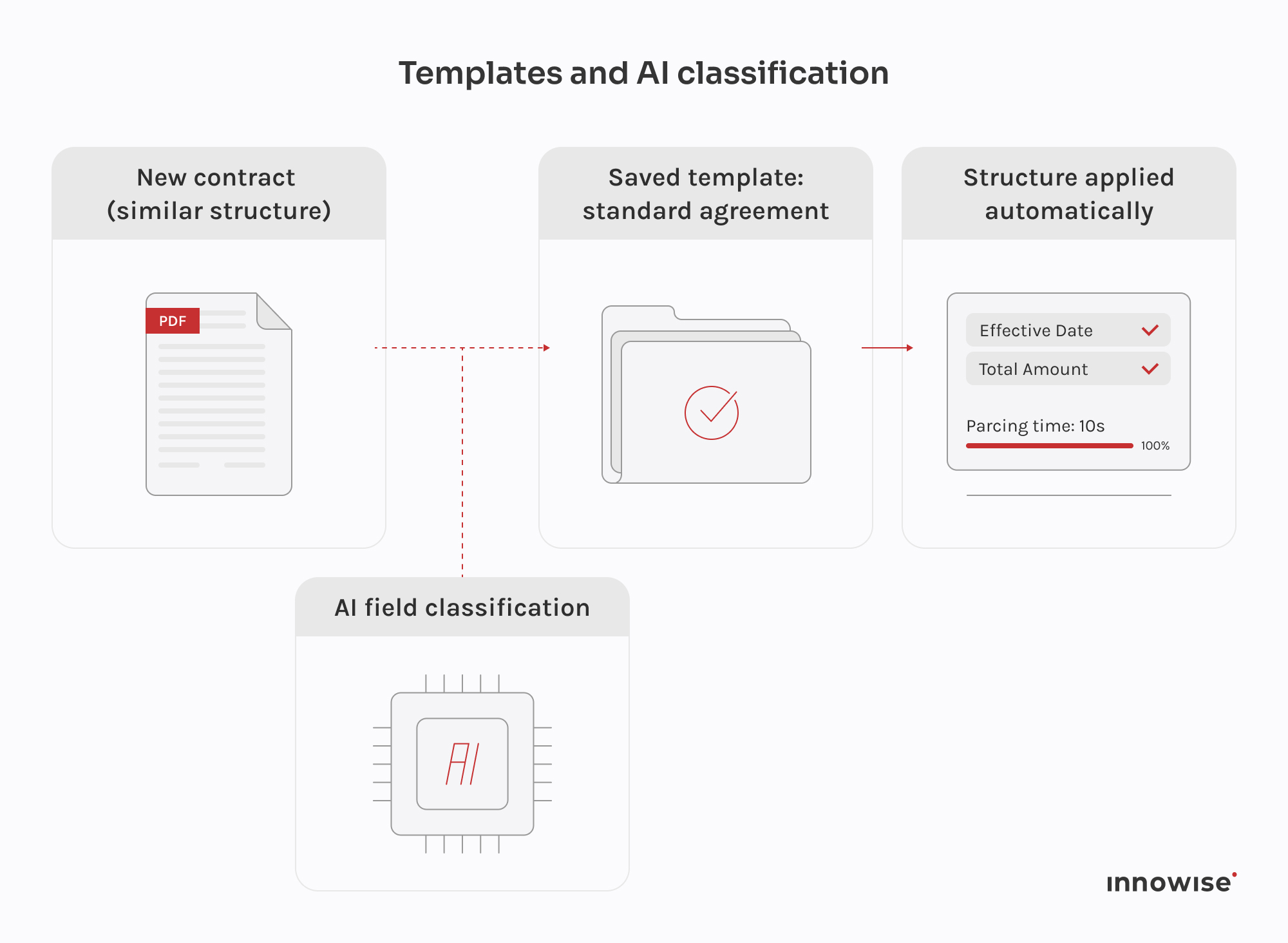
Współpraca z zespołem Leganta układała się dobrze od samego początku. Kierownik techniczny klienta był dostępny, miał jasność co do tego, czego potrzebuje i był otwarty, gdy mieliśmy inne podejście do czegoś. Weszliśmy, zapoznaliśmy się z tym, co już tam było i od tego momentu wspólnie opracowaliśmy architekturę. Na początku zakres był naprawdę otwarty, a jedynym twardym wymaganiem było MongoDB, więc wiele decyzji technicznych zapadło w wyniku ciągłej dyskusji. Ten rodzaj współpracy jest łatwiejszy, gdy druga strona dobrze zna swój produkt, a zespół Leganta tak właśnie zrobił. Pracujemy nad tym projektem od początku 2024 roku, a rytm pracy pozostał spójny przez cały czas.


