











Gracias.
Su mensaje ha sido enviado.
Procesaremos su solicitud y nos pondremos en contacto con usted lo antes posible.
El formulario se ha enviado correctamente.
Encontrará más información en su buzón.
 Contrátanos
ContrátanosSeleccionar idioma


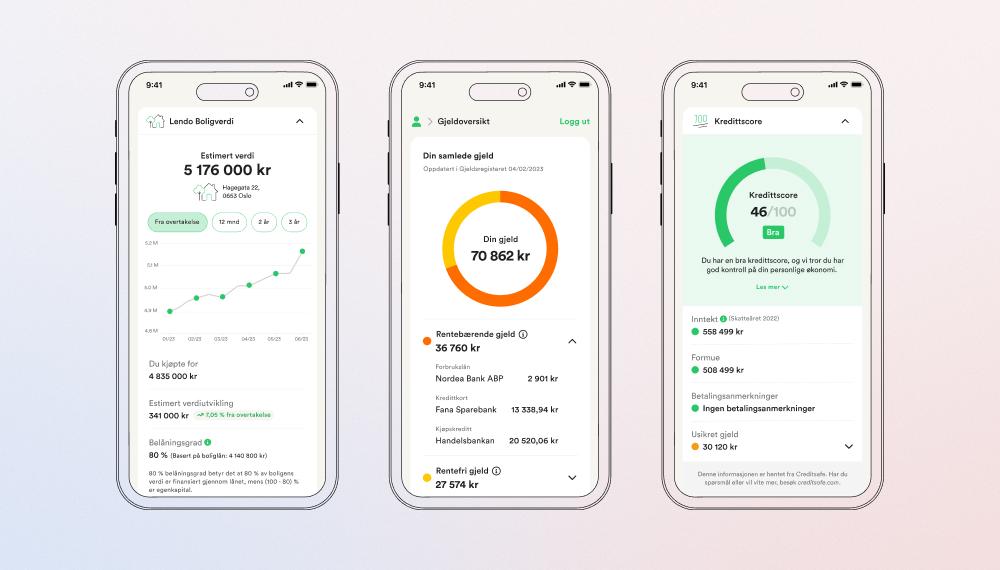

Al asumir la plena propiedad de nuestra infraestructura, aplicar las mejores prácticas del sector y modernizar todo nuestro ecosistema central, hemos pasado de una configuración dependiente del legado a una plataforma moderna y autónoma. Este cambio garantiza la estabilidad y flexibilidad necesarias para nuestra próxima fase de crecimiento.

