












Bedankt.
Uw bericht is verzonden.
We verwerken je aanvraag en nemen zo snel mogelijk contact met je op.
Het formulier is succesvol verzonden.
Meer informatie vindt u in uw mailbox.
 Inhuren
Inhuren


The Innowise team took ownership of a significant portion of the new product right from the start of our engagement. They have worked very closely with our technical lead to learn the current code base, assist in designing its architecture, and have been involved in making architectural decisions since day one of the project. Over the entire course of this collaboration, we have enjoyed good communication, with frequent daily standup meetings and regularly scheduled sync sessions.


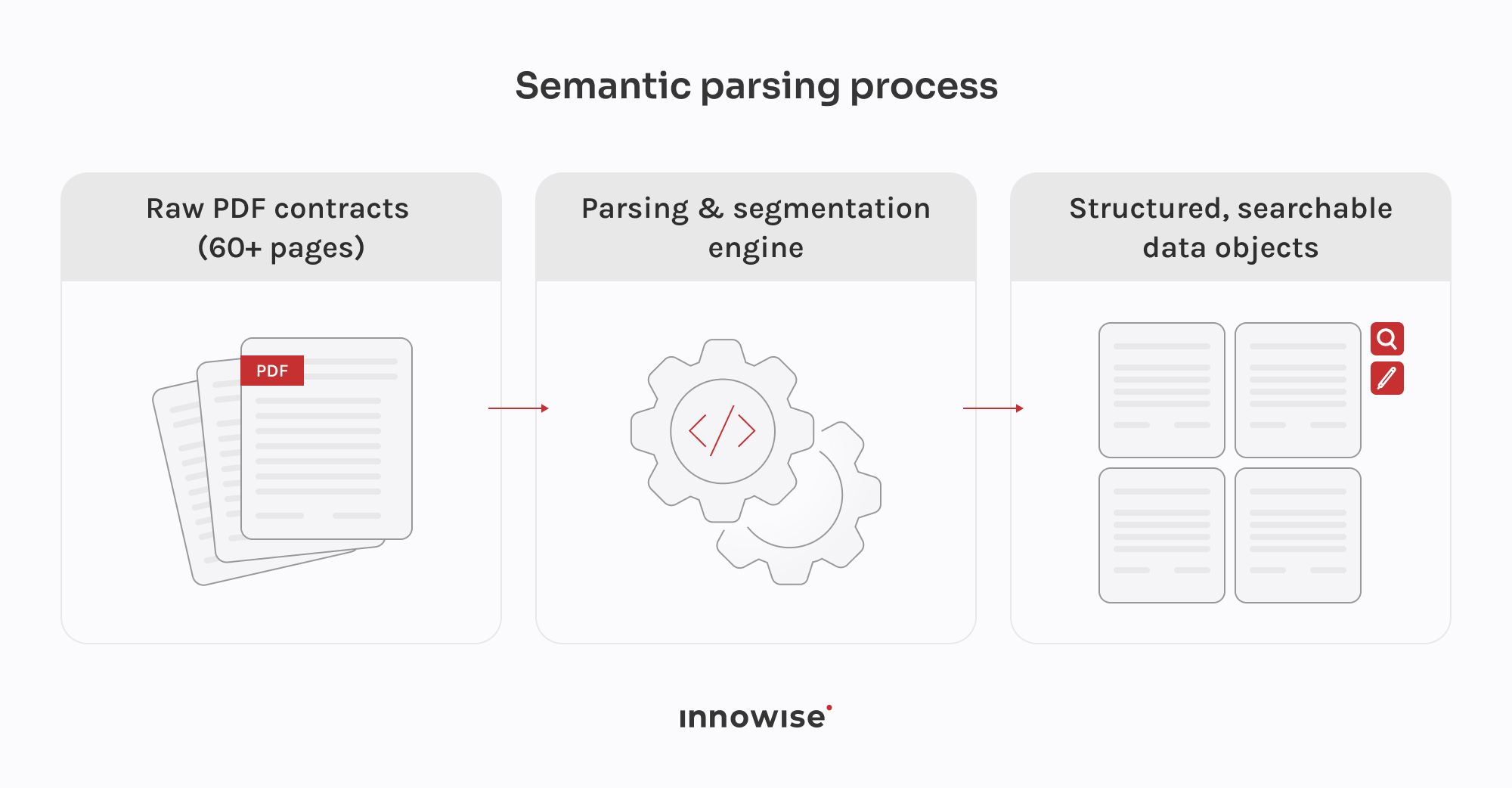
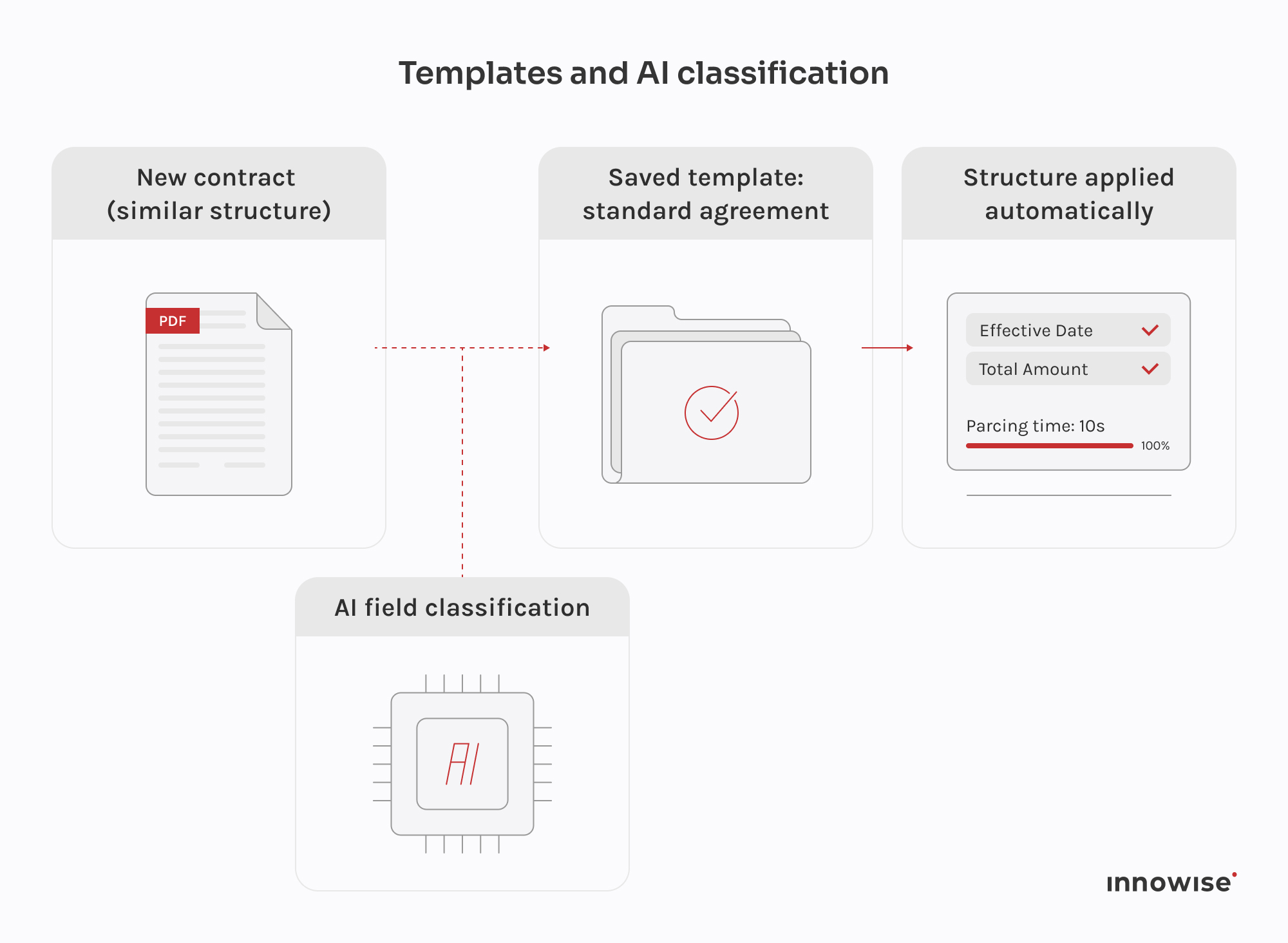
De samenwerking met het Leganta team verliep vanaf het begin goed. De technische leider van de klant was beschikbaar, duidelijk over wat ze nodig hadden en stond open als we ergens een andere kijk op hadden. We kwamen binnen, raakten vertrouwd met wat er al was en stippelden vanaf dat punt samen de architectuur uit. Het toepassingsgebied was in het begin echt open en de enige harde eis was MongoDB, dus veel van de technische beslissingen werden genomen door middel van voortdurende discussies. Dat soort samenwerking is gemakkelijker als de andere partij haar product goed kent, en dat deed het Leganta team. We werken sinds begin 2024 aan dit project en het werkritme is altijd consistent gebleven.


