












Merci !
Votre message a été envoyé.
Nous traiterons votre demande et vous contacterons dès que possible.
Le formulaire a été soumis avec succès.
Vous trouverez de plus amples informations dans votre boîte aux lettres.
 Nous recruter
Nous recruterSélection de la langue



The Innowise team took ownership of a significant portion of the new product right from the start of our engagement. They have worked very closely with our technical lead to learn the current code base, assist in designing its architecture, and have been involved in making architectural decisions since day one of the project. Over the entire course of this collaboration, we have enjoyed good communication, with frequent daily standup meetings and regularly scheduled sync sessions.


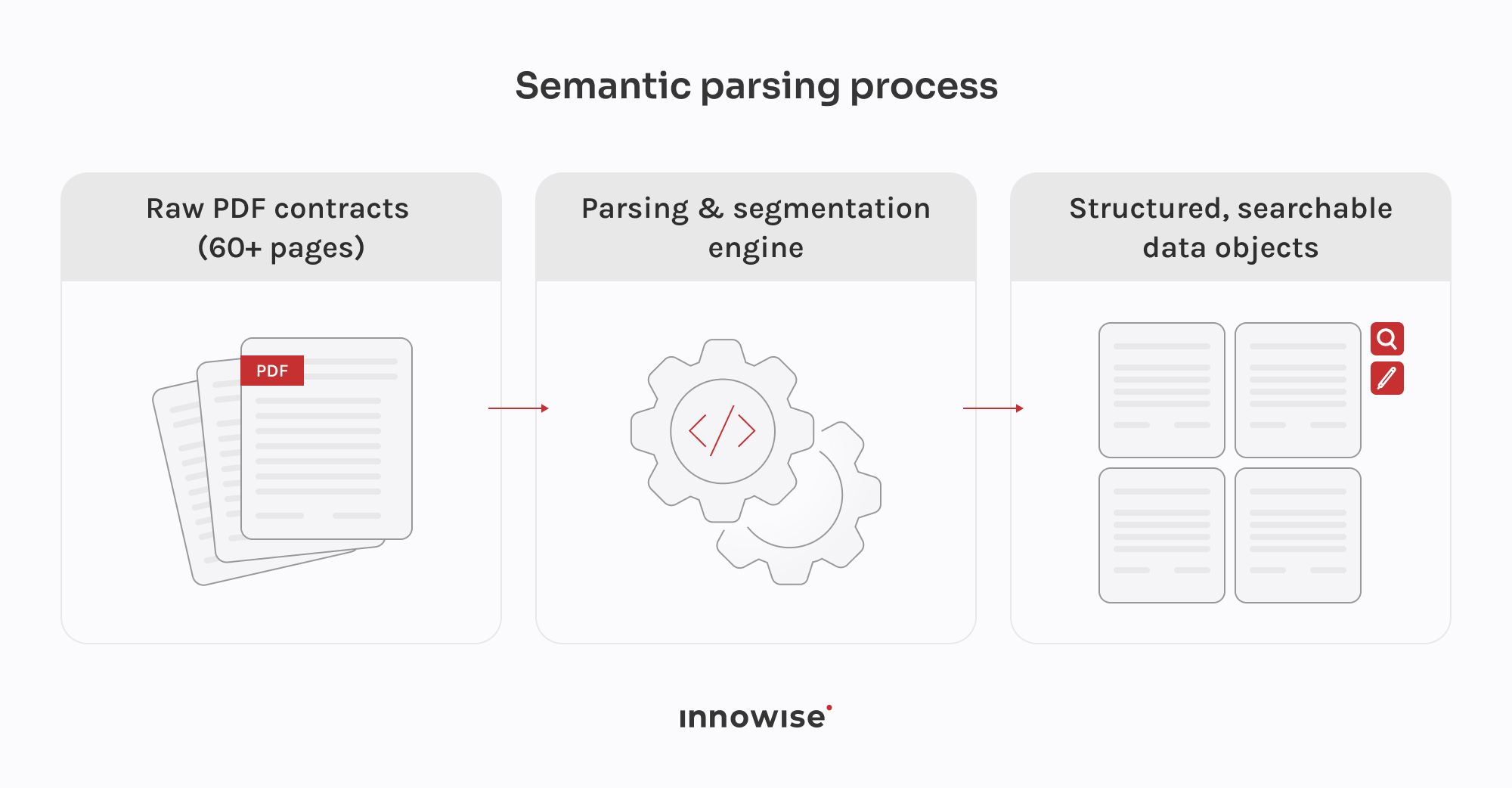
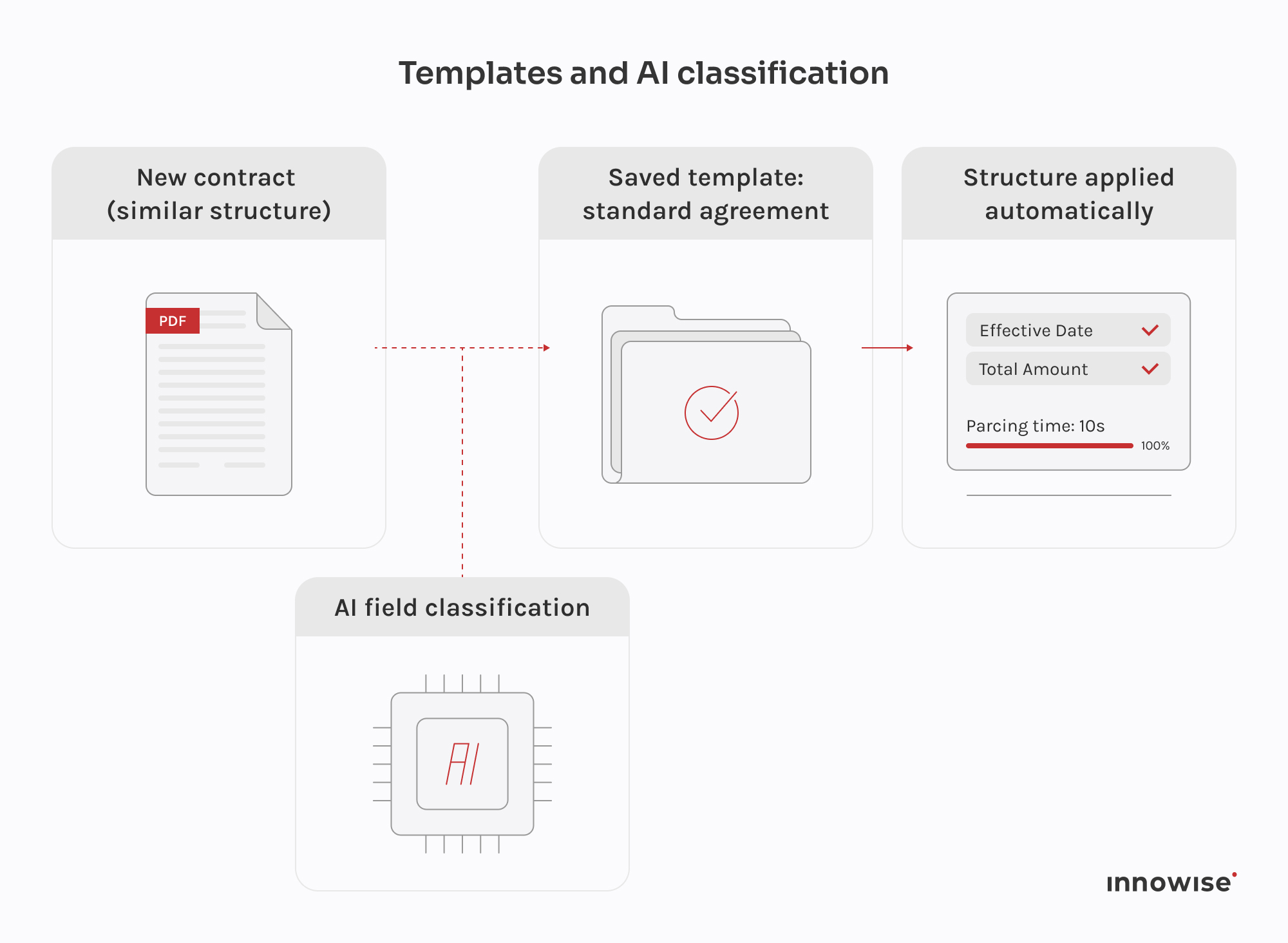
La collaboration avec l'équipe Leganta a bien fonctionné dès le départ. Le responsable technique du client était disponible, clair sur ce dont il avait besoin et ouvert lorsque nous avions un point de vue différent sur quelque chose. Nous sommes arrivés, nous nous sommes familiarisés avec ce qui existait déjà et, à partir de là, nous avons conçu l'architecture ensemble. Le champ d'application était réellement ouvert au début, et la seule exigence absolue était MongoDB, de sorte qu'une grande partie des décisions techniques ont été prises à la suite de discussions continues. Ce type de collaboration est plus facile lorsque l'autre partie connaît bien son produit, ce qui était le cas de l'équipe de Leganta. Nous travaillons sur ce projet depuis le début de l'année 2024, et le rythme de travail est resté constant tout au long du projet.


