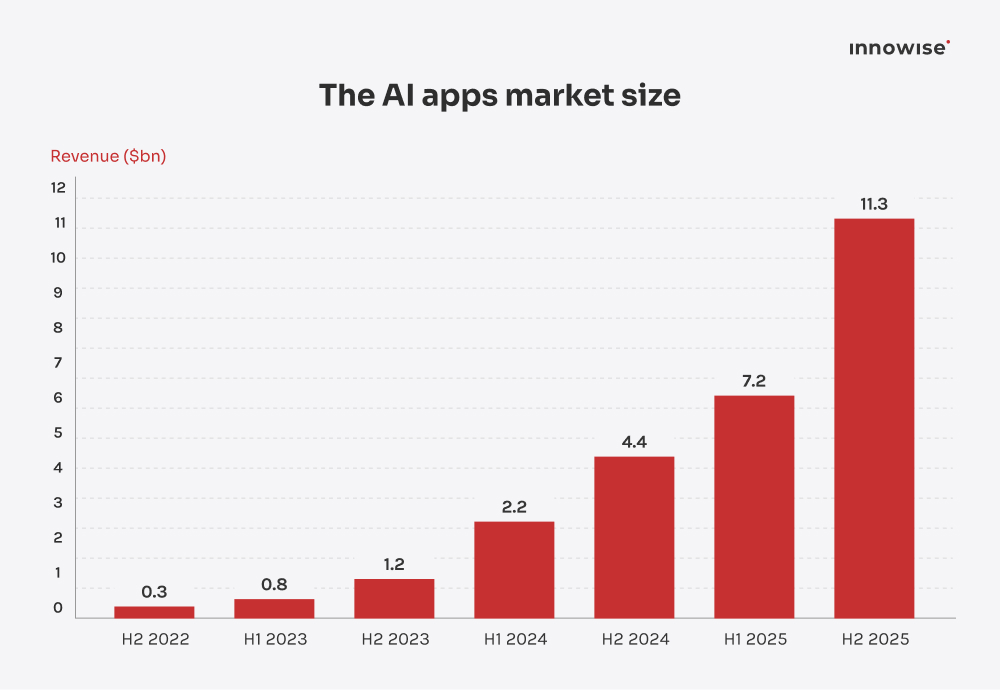
Primair gebruik
Classificatie, regressie, voorspelling, afwijkingsdetectie, aanbeveling
Chatten, zoeken, samenvatten, copilots, inhoud genereren, document V&A
Programmeertaal
Python, R
Python, JavaScript / TypeScript
Stapel kernmodellen
Scikit-learn, XGBoost, PyTorch, TensorFlow
PyTorch, TensorFlow, Knuffelgezicht Transformers
Gegevenslaag
Pandas, NumPy, functie pijplijnen
Pandas, NumPy, document parsing, chunking, embeddings
Dienen/API-laag
FastAPI, Flask
FastAPI, Flask, vLLM, Ollama
App UI/prototyping
Jupyter-notitieboek, Streamlit, webapp
Gradio, Streamlit, webapp
Opslag
PostgreSQL, MongoDB, objectopslag
PostgreSQL, MongoDB, Pinecone, Qdrant, Milvus, pgvector
Ophaallaag
Meestal niet nodig
Vectoropslag/vectorindex, inbeddingen, reranking
Model orkestratie
Batchjobs, modeleindpunten en geplande pijplijnen
LangChain, LangGraph, LlamaIndex, Semantische kernel
Experiment volgen/evaluatie
MLflow, offline statistieken, A/B-testen
MLflow, snelle evaluatie, kwaliteitscontroles van reacties, tracering
Containerisatie
Docker
Docker
Orkestratie/schaling
Kubernetes
Kubernetes
Cloud platform
AWS, Azure, Google Cloud
AWS, Azure, Google Cloud
Monitoring & Onderhoud
Logboeken, latentie, nauwkeurigheid, drift, inframetriek
Logs, latentie, tokengebruik, responskwaliteit, inframetriek
CI/CD
GitHub Acties, GitLab CI, Jenkins
GitHub Acties, GitLab CI, Jenkins
Testen
Eenheidstests, integratietests, belastingtests
Eenheidstests, integratietests, belastingstests, prompt/uitvoer evaluatie
 Inhuren
Inhuren