 Inhuren
Inhuren
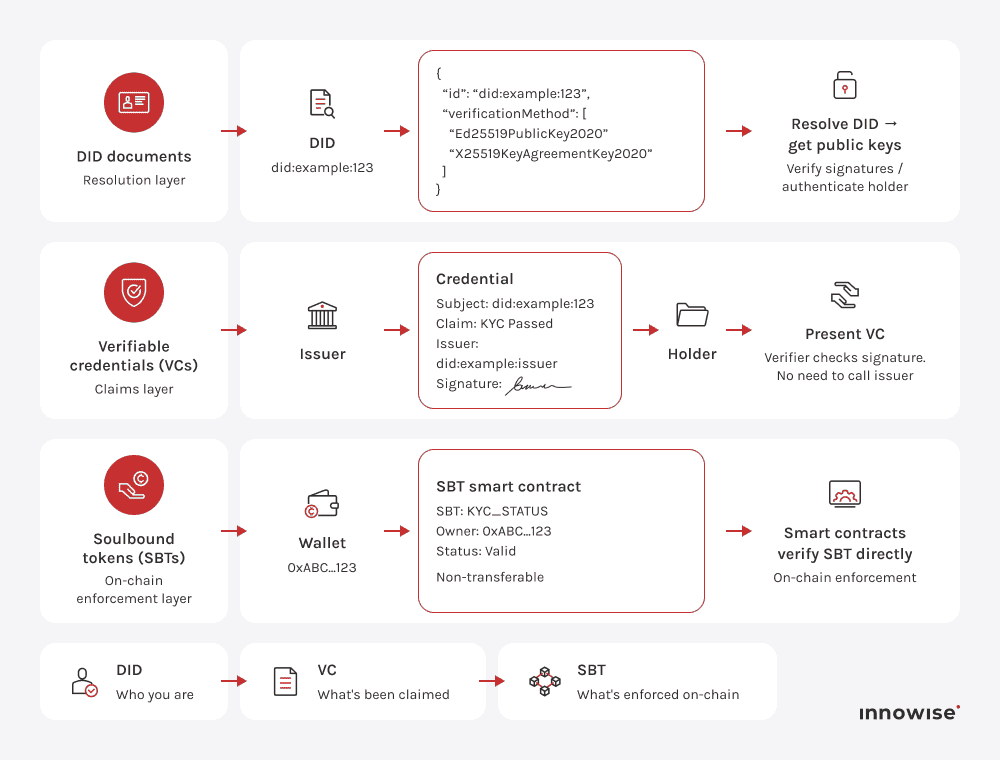




Een gedecentraliseerde identifier is een unieke, herleidbare identifier die verwijst naar een DID-document dat openbare sleutels en verificatiemethoden bevat. Hiermee kunnen entiteiten hun identiteit of controle bewijzen zonder afhankelijk te zijn van een centrale autoriteit. In de praktijk vervangt het het opzoeken in een database door cryptografische verificatie.












Bedankt.
Uw bericht is verzonden.
We verwerken je aanvraag en nemen zo snel mogelijk contact met je op.
