 Hire us
Hire us
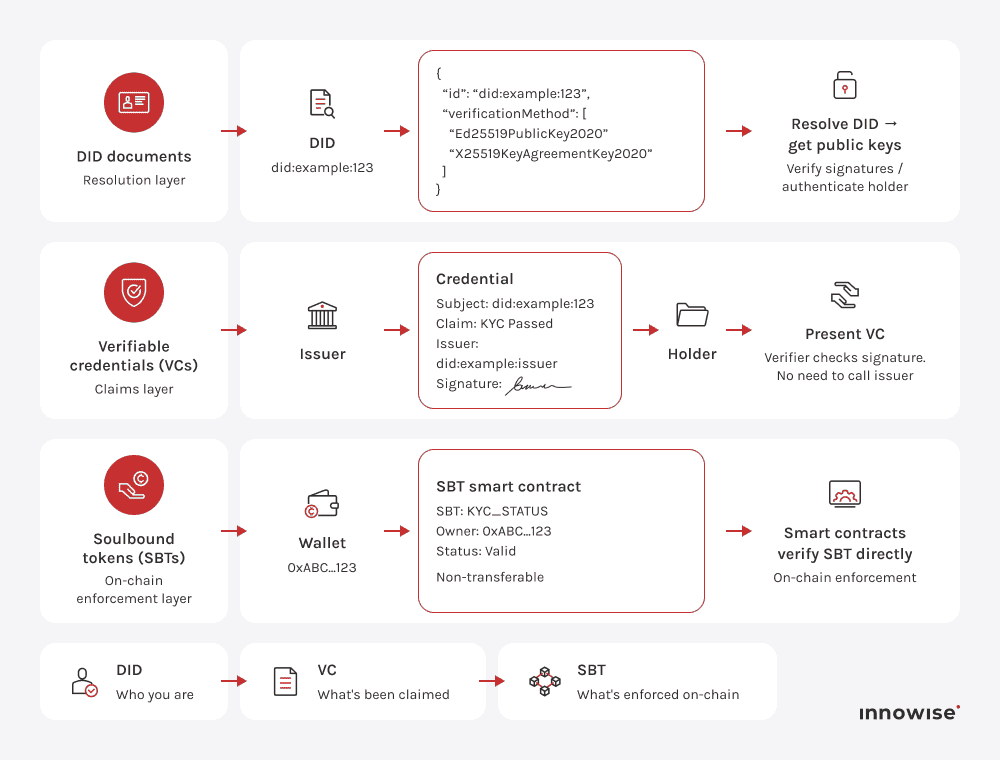




A decentralized identifier is a unique, resolvable identifier that points to a DID document containing public keys and verification methods. It allows entities to prove identity or control without relying on a central authority. In practice, it replaces database lookups with cryptographic verification.












Thank you!
Your message has been sent.
We’ll process your request and contact you back as soon as possible.
