 Contrátanos
Contrátanos
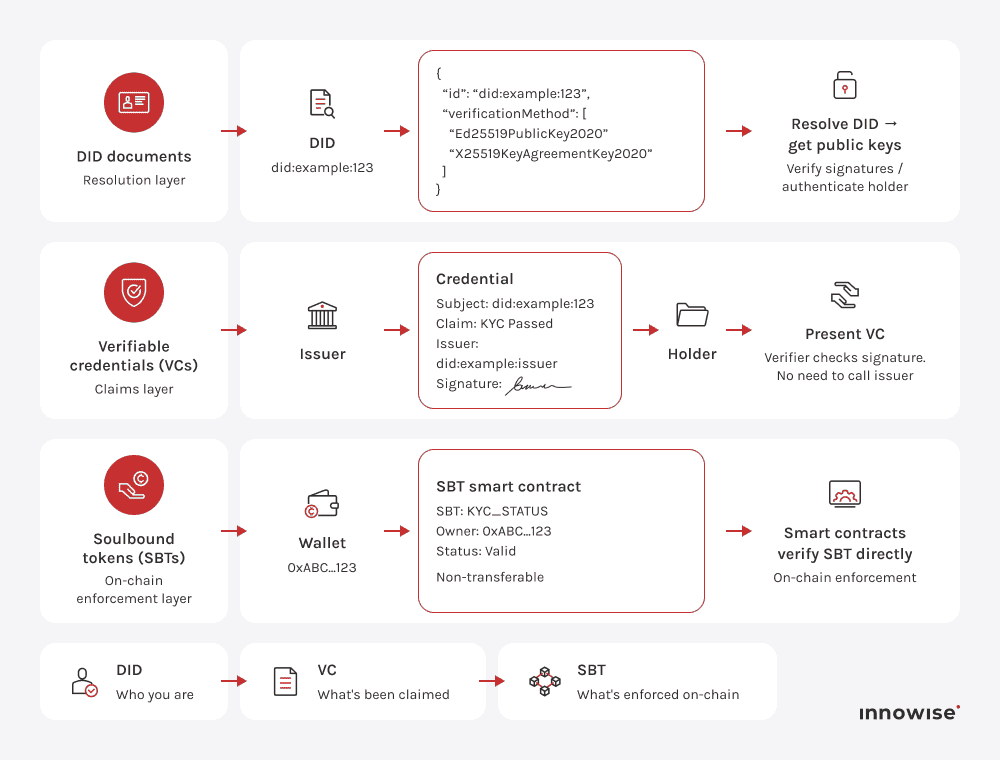




Un identificador descentralizado es un identificador único y resoluble que apunta a un documento DID que contiene claves públicas y métodos de verificación. Permite a las entidades demostrar su identidad o control sin depender de una autoridad central. En la práctica, sustituye la consulta de bases de datos por la verificación criptográfica.












Gracias.
Su mensaje ha sido enviado.
Procesaremos su solicitud y nos pondremos en contacto con usted lo antes posible.
