Laat uw contactgegevens achter, dan sturen we u ons overzicht per e-mail.
Ik geef toestemming voor het verwerken van mijn persoonlijke gegevens om gepersonaliseerd marketingmateriaal te sturen in overeenstemming met de Privacybeleid. Door de inzending te bevestigen, gaat u akkoord met het ontvangen van marketingmateriaal
Bedankt.
Het formulier is succesvol verzonden. Meer informatie vindt u in uw mailbox.
Innowise is een internationaal full-cycle software ontwikkelingsbedrijf opgericht in 2007. We zijn een team van IT professionals die software ontwikkelen voor andere professionals wereldwijd.
Innowise is een internationaal full-cycle software ontwikkelingsbedrijf opgericht in 2007. We zijn een team van IT professionals die software ontwikkelen voor andere professionals wereldwijd.
AI is reshaping data processes: automating tedious tasks like cleaning, transforming, and generating data, freeing up teams to focus on insights and strategy.
Data architecture is evolving rapidly: decentralized models (like Data Mesh) and unified systems (like Data Fabric) are making data management more flexible and scalable than ever.
Real-time insights are now a necessity: businesses need to process and act on data as it arrives to stay competitive and responsive to immediate opportunities or risks.
Cloud strategies are diversifying: hybrid and multi-cloud environments offer businesses the flexibility they need, but they also require robust governance to manage complexity and costs.
Data is no longer just for analysts: self-service tools, intuitive visualizations, and automated insights are empowering non-technical teams to make data-driven decisions. Such data democratization is transforming company-wide operations.
Let me kick things off with a bold statement: 2026is the year of reckoning for the big data industry. We’ve spent the past decade experimenting with every shiny new tech under the sun: AI, IoT, cloud platforms, and all those buzzwords. But guess what? It’s time to put up or you’ll miss the boat. If your company isn’t already figuring out how to turn that massive flood of data into something usable, you’re going to get left in the dust.
2026 is the time to make these tools work for you and stay ahead of the curve. Curious about which trends to watch? Let’s dive in.
Top 15 + big data trends shaping 2026
In 2026, big data becomes a key driver of business value, and you’ll find it impacting every industry out there. From AI-driven analytics copilots to real-time edge processing, these trends define the big data future that’s already unfolding. They will shape your business success, so read this piece till the end.
1. Generative AI for data engineering & analytics
One of the most impactful future trends in big data analytics is the rise of Generative AI. While it’s not perfect yet, GenAI is already tackling the most time-consuming and tedious parts of data engineering. AI won’t eliminate data quality challenges entirely, but it can significantly reduce the hours your team spends on data preparation.
AI is now being embedded into data pipelines, capable of automating tasks like data cleaning, filling missing gaps (imputation), and transforming data. This means you’ll have clean, ready-to-use data at a fraction of the time. For instance, platforms like Databricks en Snowflake already include built‑in functionality for generative‑AI‑enabled pipelines. It helps organisations automate data transformation, gap‑filling, and delivery of AI‑ready datasets.
Pro tip:
Start integrating AI tools into your data pipelines to automate cleaning and transformation.
Invest in platforms with generative AI capabilities to fill data gaps and enhance accuracy.
Encourage your data team to focus on strategic analysis, using AI-driven insights to drive faster decisions.
Continuously monitor AI outputs to ensure data quality and align them with business objectives.
Let’s explore how data can solve your business challenges
2. Data Mesh + Data Fabric to build the data-architecture backbone
Relying on outdated data architectures will hold you back. The key to staying competitive is adopting Data Mesh and Data Fabric.
Data Mesh decentralizes data ownership, letting domain teams manage and serve their own data, cutting out the bottleneck of central IT. Data Fabric connects all data sources (cloud, on-prem, edge) into a cohesive system with automated metadata, lineage, and integration. Together, they create a scalable, flexible architecture that enables agility without sacrificing control.
To make this work, start by identifying key domains within your business that can take ownership of their own data.
Implement a metadata layer that ensures all data is discoverable, compliant, and easy to manage.
Invest in tools and training to help domain teams fully embrace data ownership and avoid chaos.
Most importantly, focus on fostering a culture where data is treated as a product, with clear ownership and collaboration.
While Data Mesh defines the architecture for decentralization, it works best when combined with a “data-as-a-product” mindset, where each dataset is owned, documented, and managed like a real product.
3. Data as a product
Data Mesh gives you the structure. Data as a Product gives you discipline. In 2026, smart companies don’t just decentralize data, they manage it like a product, with clear ownership, documentation, and measurable value. While many companies are still working to centralize their data, the trend is rapidly moving away from data buried in random spreadsheets or isolated databases. In a data-as-a-product mindset, every dataset has documentation, role assignment, service-level agreements, and a feedback loop for improvement.
This way, marketing knows where their campaign data lives. Finance trusts the revenue numbers without needing a “data reconciliation day.” And engineering finally stops acting as the bottleneck between everyone else’s dashboards.
Platformen zoals Snowflake Data Cloud en Databricks Marketplace already help teams publish, share, and even monetize data products internally or with partners. That opens new doors for collaboration and new revenue streams. Especially when your “data product” becomes something others want to buy or build on.
Pro tip:
Assign clear ownership for every major dataset, just like you would for a product feature.
Define who’s responsible for quality, documentation, and uptime.
Standardize formats and build discoverability — an internal catalog where teams can “shop” for datasets instead of asking Slack for links.
Finally, start tracking ROI for data assets: which ones generate insights, savings, or revenue.
"At Innowise, we always make sure data works for you in a way that’s practical and efficient. Our approach integrates AI, automates data workflows, and enables real-time insights, so your team isn’t bogged down by complexity. You get clean, actionable data when you need it, so you can make decisions based on facts."
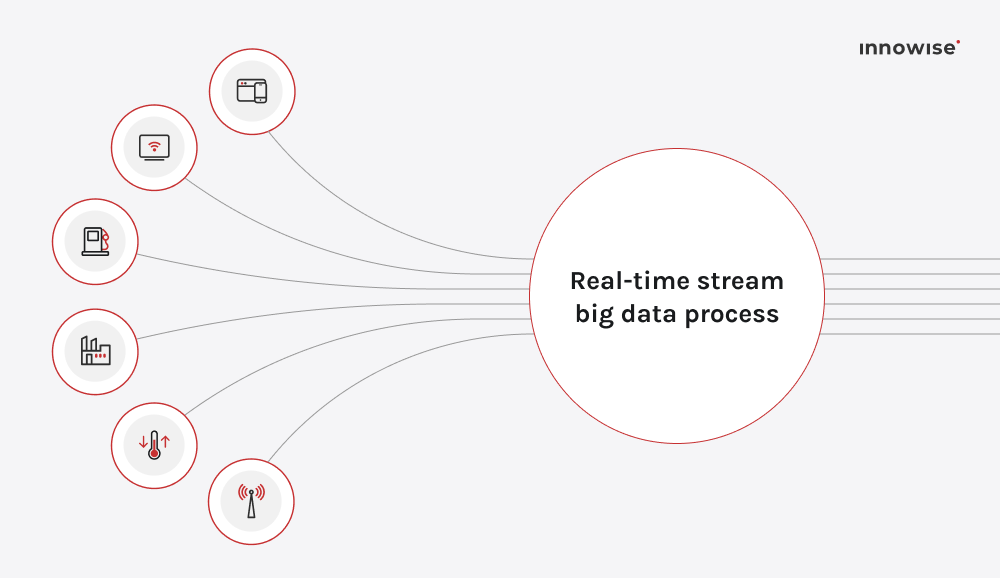
The next on the list of future trends in big data isreal‑time analytics. While the concept has been under development for years, by 2026, it will be rapidly evolving from a competitive advantage into a core necessity for organisations that demand instantaneous insights. When you process data the moment it arrives, instead of waiting for batches, you unlock the ability to act on events, signals, and patterns as they happen. For the big‑data arena, this means streaming high‑volume data sources (IoT sensors, user interactions, logs) through pipelines that analyse and respond within seconds or milliseconds.
The market backs this shift. The global streaming analytics sector was valued at $23.4 billion in 2023 and is projected to grow to about $ 128.4 billion by 2030, at a CAGR of roughly 28.3% between 2024 and 2030.Industries like finance, telecoms, manufacturing, and retail are already using stream‑based models for fraud detection, dynamic pricing, predictive maintenance, and customer experience optimization.
Pro tip:
Identify one or two high‑impact use cases where delay costs money or competitive advantage (e.g., inventory shifts, fraud spikes, equipment failure).
Deploy a streaming analytics proof‑of‑concept using technologies like Apache Kafka, Flink, or managed services from cloud providers.
Ensure your architecture is built for continuous ingestion and evaluation, including alerting, dashboards, and automated triggers.
Establish governance, data quality, and latency SLAs for those streams, as speed provides value only if insights are trusted and usable.
If your data strategy still treats real‑time as an “extra” and focuses heavily on batch first, 2026 will highlight the gap, believe me.
5. Graph analytics & knowledge graphs to unlock hidden relationships
Graph analytics steps into the spotlight in 2026, not as a new technology, but because its adoption is being rapidly accelerated by AI integration. Instead of treating data solely as rows and columns, organisations use graphs to understand how entities connect: customers, products, sensor nodes, fraud rings, you name it. Knowledge graphs en graph databases make this possible: they map complex relationships and expose insights traditional methods struggle to reveal. For example, a recent graph database report by Verified Market Reports explains that graph databases are now critical for real‑time processing, semantic relationships, and AI‑driven anomaly detection.
For business leaders, the key benefit is this: you uncover waarom things happen, not just dat they happen. In fraud detection, you spot the network of actors; in recommendation, you map hidden affinities; in IoT, you trace chains of failure. That power brings deeper insight, faster detection, en more strategic action.
Pro tip:
Identify a domain where relationships matter (customer‑360, supply‑chain, fraud, or IoT).
Pilot a graph model using a graph database or extend your data lake with a knowledge graph layer.
Ensure your team builds clear entity and relationship definitions (nodes & edges) and includes lineage and governance so your insights stay trustworthy.
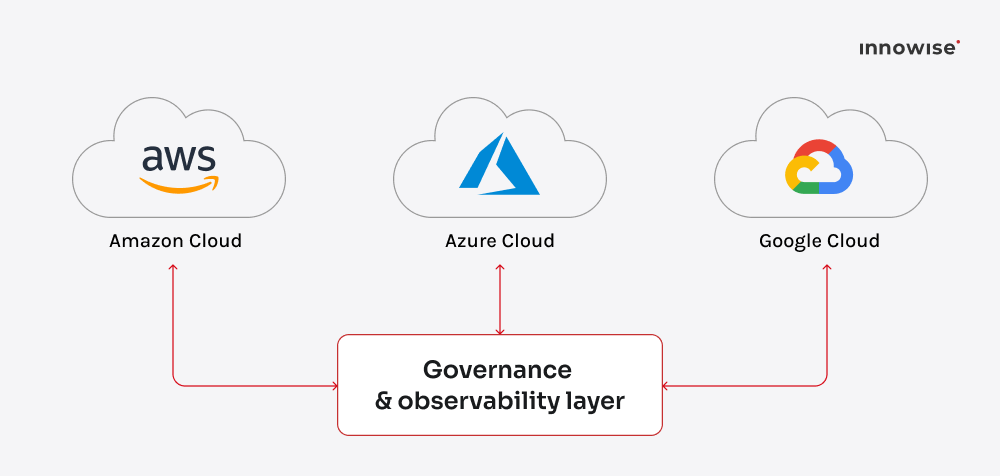
6. Multi-cloud and hybrid data strategies
In 2026, relying solely on a single cloud provider is increasingly seen as a risk, much like putting all your investment into a single stock. While many organizations still primarily use one platform, the most strategically advanced companies now play the multi-cloud game. They balance services from AWS, Azure, and Google Cloud to avoid lock-in and squeeze the best performance-to-cost ratio out of each.
Hybrid setups are rising, too. This is where organizations combine cloud services with their existing on-premises data centers. Reasons for this hybrid approach go deeper than just keeping sensitive data on-prem include:
Regional compliance: Meeting specific data residency laws (like GDPR) that mandate certain data must remain within national borders.
Legacy systems: Continuing to utilize high-performing, non-migratable legacy systems or mainframes that are critical to core operations.
Capital investment return: Maximizing the return on previous substantial investments in on-prem hardware and infrastructure.
The catch? Complexity. Spreading workloads across clouds introduces more moving parts: different APIs, billing systems, and governance rules. The winners are those who automate the orchestration and monitoring layer. Think cross-cloud query engines, unified identity management, and observability tools that track latency and cost in real time.
Pro tip:
Map your workloads and tag what truly benefits from multi-cloud: analytics, storage, or compute.
Use cloud-agnostic architectures built on open formats like Parquet, Delta, or Iceberg.
Adopt FinOps tools to monitor spend across providers and avoid “bill shock.”
Keep governance central: one access policy, one audit trail, one view of data lineage, no matter where it lives.
Generic data platforms are great. Until they start solving nothing in particular. This is why, in 2026, companies in super-competitive, high-risk, or regulated fields are done with generic tools. They want industry-tuned solutions that speak their language, handle their regulations, and deliver results instead of dashboards that look impressive and mean little.
So, why are companies suddenly demanding these specialized solutions in 2026? It really boils down to three big things:
Regulatory pressure: To stay legal and compliant without custom coding, companies need solutions with governance frameworks already baked in for their specific sector.
AI-powered domain models: Because AI is only as good as its training, organizations require solutions that come with pre-trained domain expertise and vocabulary to ensure accurate insights.
Demand for pre-built expertise: Frankly, organizations are tired of wasting time and money teaching generic tools how their industry works. They want solutions with pre-packaged connectors, data dictionaries, and compliance frameworks that fit straight into their daily workflows. It’s all about getting results and eliminating that painful, costly translation step.
That’s why the market is shifting toward domain-specific data products: pre-built models, connectors, and compliance frameworks that fit straight into real workflows. This specialization is already demonstrating massive growth in vertical markets. For instance, according to Visiongain, the healthcare analytics market alone will reach $101 billion by 2031, driven by this kind of specialization.
Pro tip:
Stop chasing one-size-fits-all analytics platforms. Instead, pick tools built for your industry’s data quirks: from EMR standards in healthcare to AML rules in banking.
Push your vendors on domain expertise, not just their tech stack.
Build small, outcome-driven pilots around your biggest operational pain points, and scale what actually works.
8. Edge computing for big data
In 2026, the demand for immediate, automated action is paramount. Though the cloud is still vital, companies are realizing it costs too much time and money to send every single byte of data to a distant server for processing.
Edge computing is the fix. It brings data processing closer to where it’s generated: sensors, machines, devices, even cars. Instead of pushing terabytes across the network, you process the important stuff locally and act instantly.
Why is this trend exploding nu?
IoT explosion: Billions of sensors mean centralized processing is just too expensive and slow.
AI at the edge: Lightweight models let the AI make real-time decisions right on the device, skipping the cloud delay.
Real-time mandate: In high-stakes areas (like catching equipment failure), milliseconds matter.
This matters most for industries where speed is life: smart factories that adjust production lines on the fly, hospitals that monitor patients in real time, or retail chains that manage pricing dynamically based on local demand. And the money backs it up: IDC forecasts global spending on edge computing solutions to grow at ~13.8% CAGR and reach nearly $380 billion by 2028.
The smartest organizations aren’t replacing the cloud; they’re completing it. They use a hybrid setup: local processing for speed, cloud storage for scale. The result is beautiful: lower latency, reduced bandwidth costs, and faster decisions that actually move the needle.
Pro tip:
Start with one area where latency hurts. Maybe quality control in production or predictive maintenance in logistics.
Deploy edge analytics there and connect it to your central cloud system.
Define clear rules for what gets processed locally versus centrally, and keep governance consistent across both.
9. Synthetic data and privacy-enhancing tech
In 2026, access to real-world data is trickier than ever: privacy laws are stricter, regulators are watchful, and users are far less forgiving. That’s why we need synthetic data.
The trend is exploding now because the GenAI boom has finally made synthetic data high-quality enough to reliably mimic complex, real-world information. Companies are increasingly relying on this artificial, statistically accurate data to train massive AI models faster and cheaper than traditional methods, all while automatically satisfying tough compliance needs like GDPR and the EU’s AI Act.
Synthetic data tools are everywhere: from finance firms training fraud detection models to healthcare companies running AI diagnostics without exposing patient data. Gartner verwacht that by 2030, synthetic data will surpass real data in AI training, because it’s safer, faster, and easier to scale.
Pro tip:
Use synthetic data in areas where compliance blocks access to real information (healthcare, finance, or HR analytics).
Integrate PETs (Privacy-Enhancing Technologies) into your pipeline early, not as an afterthought.
Run pilot projects comparing model performance on synthetic versus real data, and track how it impacts accuracy and bias.
Take control of your data — reduce costs, increase efficiency
In 2026, analytics finally feels human. AI copilots and narrative visualization tools now turn data into clear stories instead of endless charts. Tools like Power BI Copilot, Tableau GPT, camelAI, and Looker’s GenAI layer can query, summarize, and explain insights in plain language.
Think of them as your data analyst. You can ask, “How did revenue trend this quarter?” or “Which campaign brought the highest ROI?” and get instant answers in plain language. Tools like Power BI Copilot, Tableau GPT, en camelAI already do this, connecting large language models directly to your company’s data.
Pro tip:
Integrate copilots into your analytics stack, connect them to verified datasets, and redesign dashboards around narratives, not metrics.
Train teams to validate AI outputs and focus on the “why” behind every number.
11. Cloud data warehousing and the rise of the lakehouse
In 2026, the line between data lakes and warehouses has blurred. The new standard is lakehouse architecture, which is a hybrid model that combines the scalability of data lakes with the structure and performance of warehouses. You can store unstructured data, query it with SQL, and run machine learning workloads. All in one place. Without juggling ten different platforms.
Vendors like Databricks, Snowflake, en Google BigQuery are leading the charge here.
Pro tip:
If your infrastructure still splits data between lakes and warehouses, start consolidating.
Adopt a lakehouse solution that fits your stack and train your team to query across both structured and unstructured datasets.
Prioritize open formats like Parket en Deltameer to avoid vendor lock-in.
And once you’re set up, start layering advanced analytics and machine learning directly on top. That’s where the real ROI lives.
12. Data observability and DataOps
In 2026, managing data pipelines without observability is like flying a plane with the dashboard turned off. You might move fast, but you have no idea what’s breaking. Data observability is how teams get visibility into the health, freshness, and reliability of their data. It tells you when something’s wrong, why it happened, and how to fix it before dashboards start showing nonsense.
So, why is this essential nu? Because you can’t have governance or compliance without it.
You need to govern: Observability tools track the entire data journey (or lineage), providing the proof you need to enforce quality standards and policies across your company.
You need to comply: Since the tools log everything (who touched the data, how it was transformed) they generate the exact audit trail required to satisfy regulators (for things like GDPR).
This goes hand-in-hand with DataOps, which automates things like testing and deployment. Together, observability and DataOps give you a reliable, compliant, and rock-solid data backbone with fewer surprises and faster recovery times.
Pro tip:
Start by instrumenting your key data pipelines with observability tools that track freshness, lineage, and anomalies.
Treat data pipelines like production systems, monitor them continuously, not just when something breaks.
Pair observability with DataOps practices: automate testing, implement version control for transformations, and create clear ownership of each dataset.
13. FinOps for data and AI
Have cloud bills ever kept you awake at night? As data volumes explode and AI workloads multiply, FinOps (financial operations for cloud and data) becomes essential. The goal is simple: understand where every dollar in your data ecosystem goes and make sure it’s actually buying business value, not just bigger servers.
Training large models, storing petabytes of data, and running endless queries can drain budgets fast. FinOps teams now use analytics and automation to track costs in real time, spot inefficiencies, and forecast usage across departments. Cloud providers even offer native tools for this (AWS Cost Explorer, Google Cloud Billing, Azure Cost Management), but the real gains come from integrating financial metrics directly into your data workflows.
Pro tip:
Bring FinOps into your data strategy early.
Tag every dataset, pipeline, and model by cost center and business owner.
Track spend on storage, compute, and AI training with real-time dashboards.
Encourage your data teams to monitor resource usage as closely as they do performance metrics.
And when in doubt, automate. Use AI-driven recommendations to shut down idle clusters or rebalance workloads.
14. Explainable and responsible AI
In 2026, AI runs so much of business that “just trust the model” doesn’t fly anymore. Boards, regulators, and customers all expect transparency. They want to know waarom an algorithm made a decision, not just the result. That’s why Explainable AI (XAI) en Responsible AI are gaining traction. Together, they make machine learning less of a black box and more of a system you can govern.
Banks already use explainable models to justify credit decisions to auditors. Healthcare providers rely on them to show how diagnostic algorithms reach conclusions. Even HR systems are under scrutiny to prove fairness in hiring recommendations. When decisions affect people or profits, blind faith in AI isn’t strategy; it’s a risk.
Pro tip:
Set up internal policies for explainability across all AI projects.
Require every model to have a clear rationale for its predictions and a record of its training data.
Use explainability tools like SHAP, LIME, or your cloud provider’s native XAI features.
And make responsibility part of your workflow: include legal, compliance, and HR voices in your AI governance board.
15. Multi-modal analytics
By 2026, big data development will move beyond tables and dashboards into a new era of multi-modal analytics. Here, text, images, video, and sensor data combine to create a complete, context-rich picture. Instead of analyzing customer feedback and sales numbers separately, teams can now correlate call transcripts, product photos, and user behavior in a single workspace.
Sounds like sci-fi, right? But platforms like Databricks MosaicML, Anthropic’s Claude for data, en OpenAI’s GPT-4 Turbo with vision already handle multi-format data inputs. The result is cool. Context-rich insights feel almost intuitive. Imagine predicting equipment failures by cross-analyzing vibration logs, thermal images, and maintenance notes. That’s what multi-modal analysis enables.
Pro tip:
Audit where your data lives and how fragmented it is across formats.
If your analytics only focus on structured data, start adding unstructured sources: customer calls, images, and video feeds.
Invest in a platform that supports multi-modal input, ideally one built with vector databases and semantic search.
And most importantly, encourage teams to think beyond numbers.
Simplify your data workflows and unlock new opportunities
And the last on the list of key trends in big data is decision intelligence (DI). It blends data science, psychology, and business logic to help organizations make smarter calls faster. Instead of throwing a hundred metrics at you, DI systems model how choices lead to outcomes, then simulate scenarios before you commit.
Think of it as analytics that answers “what happens if we actually do this?”, not just “what happened last quarter?” Retailers use it to test pricing strategies before rollout. Banks use it to simulate risk exposure across portfolios. Even HR teams use DI to predict hiring and retention impact before policies go live.
The market evidences this shift: the global decision intelligence market was estimated at $15.22 billion in 2024 en zal naar verwachting $36.34 billion by 2030, growing at about a 15.4% CAGR.
Pro tip:
Start by mapping how decisions are made: who makes them, what data they use, and how success is measured.
Then identify repetitive or high-stakes areas where simulation could prevent mistakes.
Pilot a DI tool that connects business logic with live data, and define KPIs for decision outcomes, not just data accuracy.
Conclusie
So, what is the future of big data? 2026 brings a new level of maturity to it. The focus now is on choosing the tools and methods that actually create impact. Businesses that connect technology with clear goals will see faster growth and stronger results.
Use AI where it saves time and improves accuracy. Build a data mesh that helps teams work together instead of in silos. Invest in real-time analytics that help you act at the right moment, not after the fact.
The leaders of this year understand one thing: value comes from applying data with purpose. Pick what fits your strategy, make it work across teams, and let data become the engine that drives every smart move you make.
Philip brengt scherpe focus aan in alles wat met data en AI te maken heeft. Hij is degene die in een vroeg stadium de juiste vragen stelt, een sterke technische visie bepaalt en ervoor zorgt dat we niet alleen slimme systemen bouwen, maar ook de juiste, voor echte bedrijfswaarde.
Een diepgaande duik in de rol van frontier deployment engineer en hoe FDE's experimentele AI pilots omzetten in veilige, meetbare en schaalbare AI productiesystemen.
Denk je dat virtuele showrooms gewoon een coole gimmick zijn? Denk er nog eens over na. Dit is hoe ze de verkoop stimuleren en de modedetailhandel transformeren.
Ontdek de toptrends op het gebied van softwareontwikkeling voor 2026. Ontdek de nieuwste technologieën en inzichten die de software-industrie zullen transformeren!
Ontdek de toptrends op het gebied van softwareontwikkeling voor 2026. Ontdek de nieuwste technologieën en inzichten die de software-industrie zullen transformeren!
 Inhuren
Inhuren