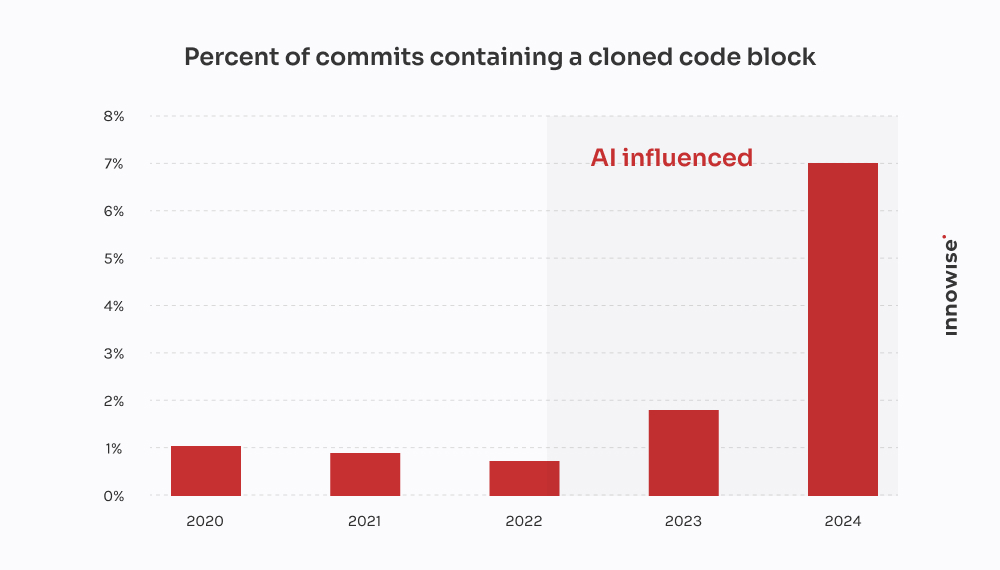
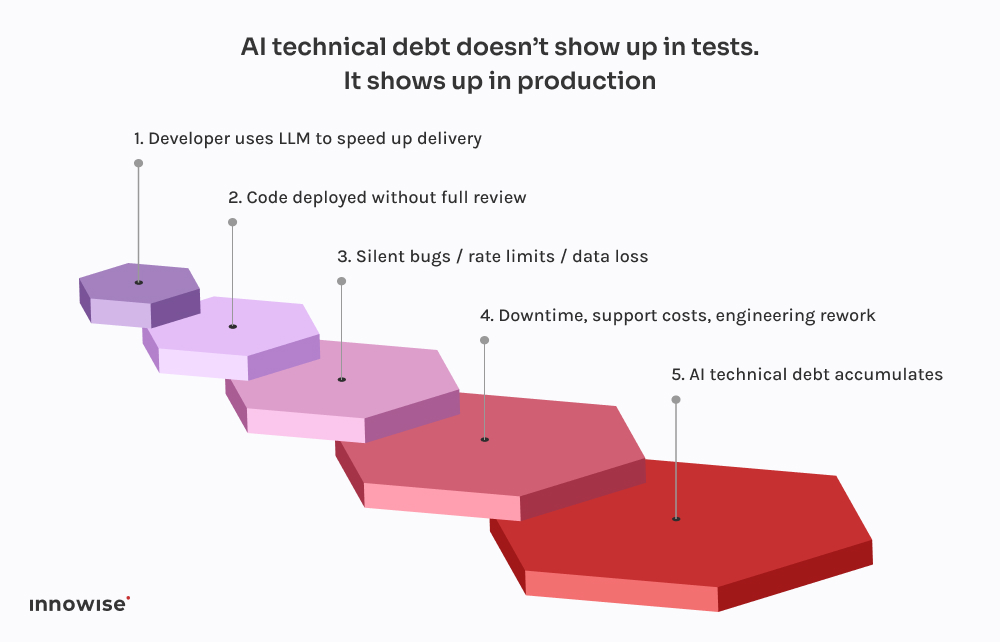
Ta pochodzi od szybko rozwijającej się firmy z branży fintech.
Wprowadzali nową wersję modelu danych klientów, dzieląc jedno duże pole JSONB w Postgres na wiele znormalizowanych tabel. Dość standardowa rzecz. Ale z napiętymi terminami i niewystarczającą liczbą rąk, jeden z programistów postanowił "przyspieszyć pracę", prosząc ChatGPT o wygenerowanie skryptu migracyjnego.
Na pierwszy rzut oka wyglądało to dobrze. Skrypt przeanalizował JSON, wyodrębnił informacje kontaktowe i wstawił je do nowego pliku user_contacts tabela.
Więc go uruchomili.
Brak pracy na sucho. Żadnej kopii zapasowej. Prosto do etapu przejściowego, który, jak się okazało, udostępniał dane produkcji za pośrednictwem repliki.
Kilka godzin później obsługa klienta zaczęła otrzymywać wiadomości e-mail. Użytkownicy nie otrzymywali powiadomień o płatnościach. Inni nie mieli numerów telefonów w swoich profilach. Wtedy do nas zadzwonili.
Co poszło nie tak
Wyśledziliśmy problem w skrypcie. Wykonał on podstawową ekstrakcję, ale przyjął trzy fatalne założenia:
- Nie poradził sobie
NULL lub brakujące klucze w strukturze JSON. - Wstawił częściowe rekordy bez walidacji.
- Użyto
ON CONFLICT DO NOTHING, więc wszelkie nieudane wstawienia były po cichu ignorowane.
Wynik: o 18% danych kontaktowych został utracony lub uszkodzony. Brak dzienników. Brak komunikatów o błędach. Po prostu cicha utrata danych.
Co trzeba było naprawić
Wyznaczyliśmy niewielki zespół, którego zadaniem było rozplątanie tego bałaganu. Oto, co zrobiliśmy:
- Diagnoza i replikacja (4 godziny) Odtworzyliśmy skrypt w środowisku piaskownicy i uruchomiliśmy go w oparciu o migawkę bazy danych. W ten sposób potwierdziliśmy problem i dokładnie określiliśmy, czego zabrakło.
- Śledczy audyt danych (8 godzin) Porównaliśmy uszkodzony stan z kopiami zapasowymi, zidentyfikowaliśmy wszystkie rekordy z brakującymi lub częściowymi danymi i dopasowaliśmy je do dzienników zdarzeń, aby prześledzić, które wstawki nie powiodły się i dlaczego.
- Przepisanie logiki migracji (12 godzin) Przepisaliśmy cały skrypt w Python, dodaliśmy pełną logikę walidacji, zbudowaliśmy mechanizm wycofywania i zintegrowaliśmy go z potokiem CI klienta. Tym razem obejmowało to testy i obsługę suchych przebiegów.
- Ręczne odzyskiwanie danych (6 godzin) Niektórych rekordów nie można było odzyskać z kopii zapasowych. Wyciągnęliśmy brakujące pola z systemów zewnętrznych (interfejsy API CRM i dostawcy poczty e-mail) i ręcznie przywróciliśmy brakujące pola.
Całkowity czas: 30 godzin inżynierskich
Dwóch inżynierów, trzy dni. Koszt dla klienta: około $4,500 w opłatach za usługi.
Większym ciosem były jednak straty ponoszone przez klientów. Nieudane powiadomienia doprowadziły do braku płatności i rezygnacji. Klient powiedział nam, że wydał co najmniej $10,000 na zgłoszeniach do pomocy technicznej, rekompensatach SLA i kredytach dobrej woli za ten jeden nieudany skrypt.
Ironiczne jest to, że starszy programista mógł napisać poprawną migrację w ciągu czterech godzin. Ale obietnica szybkości AI kosztowała ich dwa tygodnie sprzątania i utratę reputacji.
 Zatrudnij nas
Zatrudnij nas