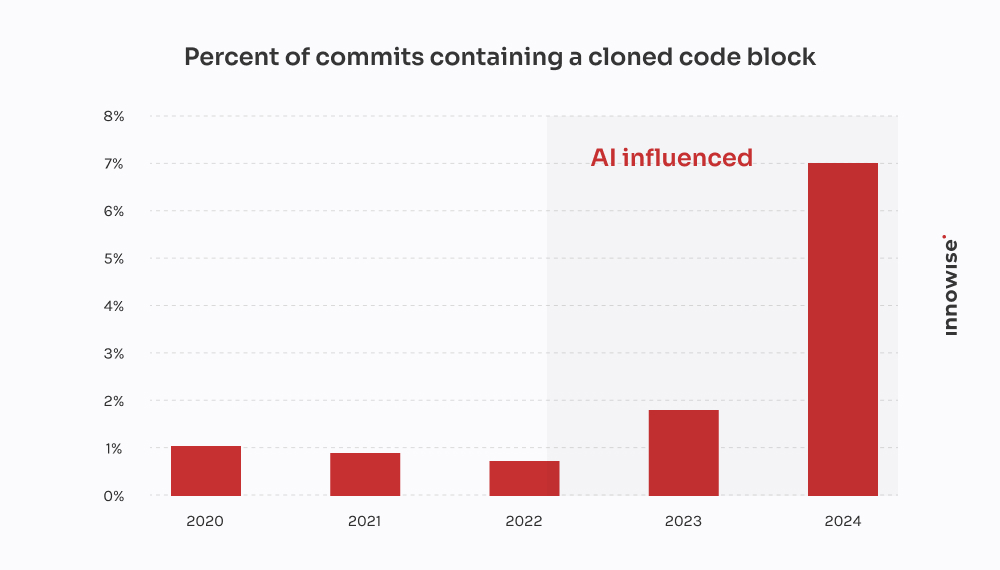
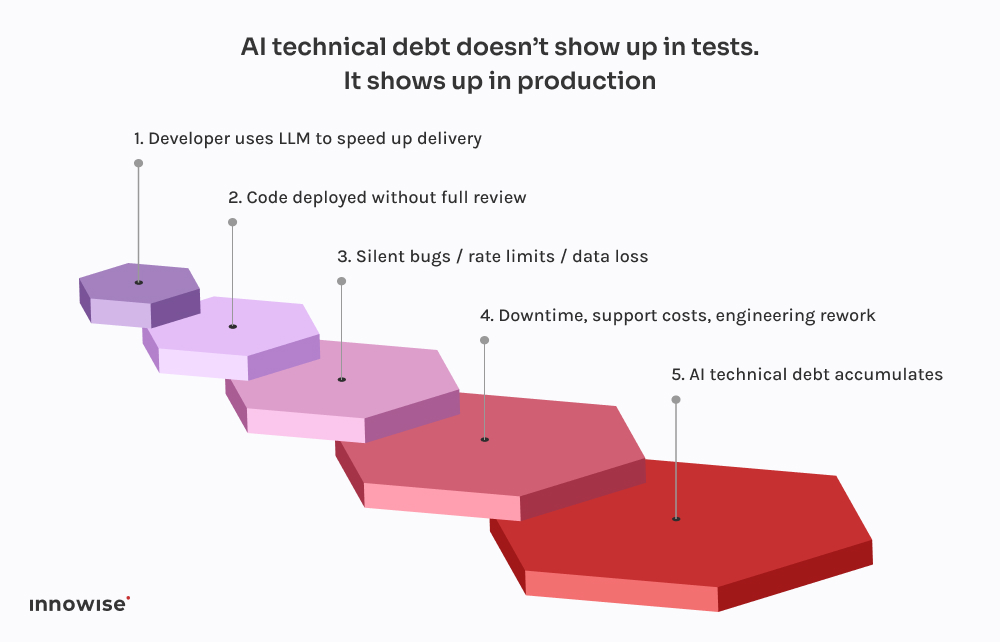
Celle-ci émane d'une entreprise de fintech à croissance rapide.
Ils étaient en train de déployer une nouvelle version de leur modèle de données clients, en divisant un grand champ JSONB dans Postgres en plusieurs tables normalisées. Un travail plutôt standard. Mais avec des délais serrés et pas assez de mains, l'un des développeurs a décidé d'accélérer les choses en demandant à ChatGPT de générer un script de migration.
En apparence, tout se passait bien. Le script analysait le JSON, extrayait les informations de contact et les insérait dans un nouveau fichier user_contacts table.
Ils l'ont donc fait fonctionner.
Pas d'essai. Pas de sauvegarde. Directement dans la phase d'essai, qui, comme il s'avère, partageait des données avec la production par l'intermédiaire d'une réplique.
Quelques heures plus tard, le service clientèle a commencé à recevoir des courriels. Les utilisateurs ne recevaient pas de notifications de paiement. D'autres avaient des numéros de téléphone manquants dans leur profil. C'est alors qu'ils nous ont appelés.
Ce qui n'a pas fonctionné
Nous avons remonté le problème jusqu'au script. Il a effectué l'extraction de base, mais il a fait trois hypothèses fatales :
- Il n'a pas géré
NULL ou des clés manquantes dans la structure JSON. - Il a inséré des enregistrements partiels sans validation.
- Il a utilisé
ON CONFLICT DO NOTHING, de sorte que les insertions qui échouent sont silencieusement ignorées.
Résultat: à propos 18% des données de contact a été perdue ou corrompue. Pas de journaux. Pas de messages d'erreur. Juste une perte de données silencieuse.
Ce qu'il a fallu faire pour réparer
Nous avons chargé une petite équipe de démêler l'écheveau. Voici ce que nous avons fait :
- Diagnostic et réplication (4 heures) Nous avons recréé le script dans un environnement sandbox et l'avons exécuté sur un instantané de la base de données. C'est ainsi que nous avons confirmé le problème et cartographié exactement ce qui manquait.
- Audit légal des données (8 heures) Nous avons comparé l'état de rupture avec les sauvegardes, identifié tous les enregistrements contenant des données manquantes ou partielles et les avons comparés aux journaux d'événements afin de déterminer les insertions qui ont échoué et les raisons de cet échec.
- Réécrire la logique de migration (12 heures) Nous avons réécrit l'intégralité du script en Python, ajouté une logique de validation complète, construit un mécanisme de retour en arrière et l'avons intégré dans le pipeline CI du client. Cette fois, nous avons inclus des tests et un support pour les essais à blanc.
- Récupération manuelle des données (6 heures) Certains enregistrements étaient irrécupérables à partir des sauvegardes. Nous avons extrait les champs manquants de systèmes externes (API de leur CRM et de leur fournisseur de messagerie) et restauré manuellement le reste.
Durée totale : 30 heures d'ingénierie
Deux ingénieurs, trois jours. Coût pour le client : environ $4,500 en frais de service.
Mais ce sont les retombées pour les clients qui ont été les plus graves. L'échec des notifications a entraîné des retards de paiement et des désabonnements. Le client nous a dit qu'il avait dépensé au moins $10,000 sur les tickets d'assistance, les compensations SLA et les crédits de bonne volonté pour ce seul script raté.
Le plus ironique, c'est qu'un développeur chevronné aurait pu écrire la migration correcte en quatre heures environ. Mais la promesse d'une vitesse de AI a fini par leur coûter deux semaines de nettoyage et d'atteinte à leur réputation.

 Nous recruter
Nous recruter