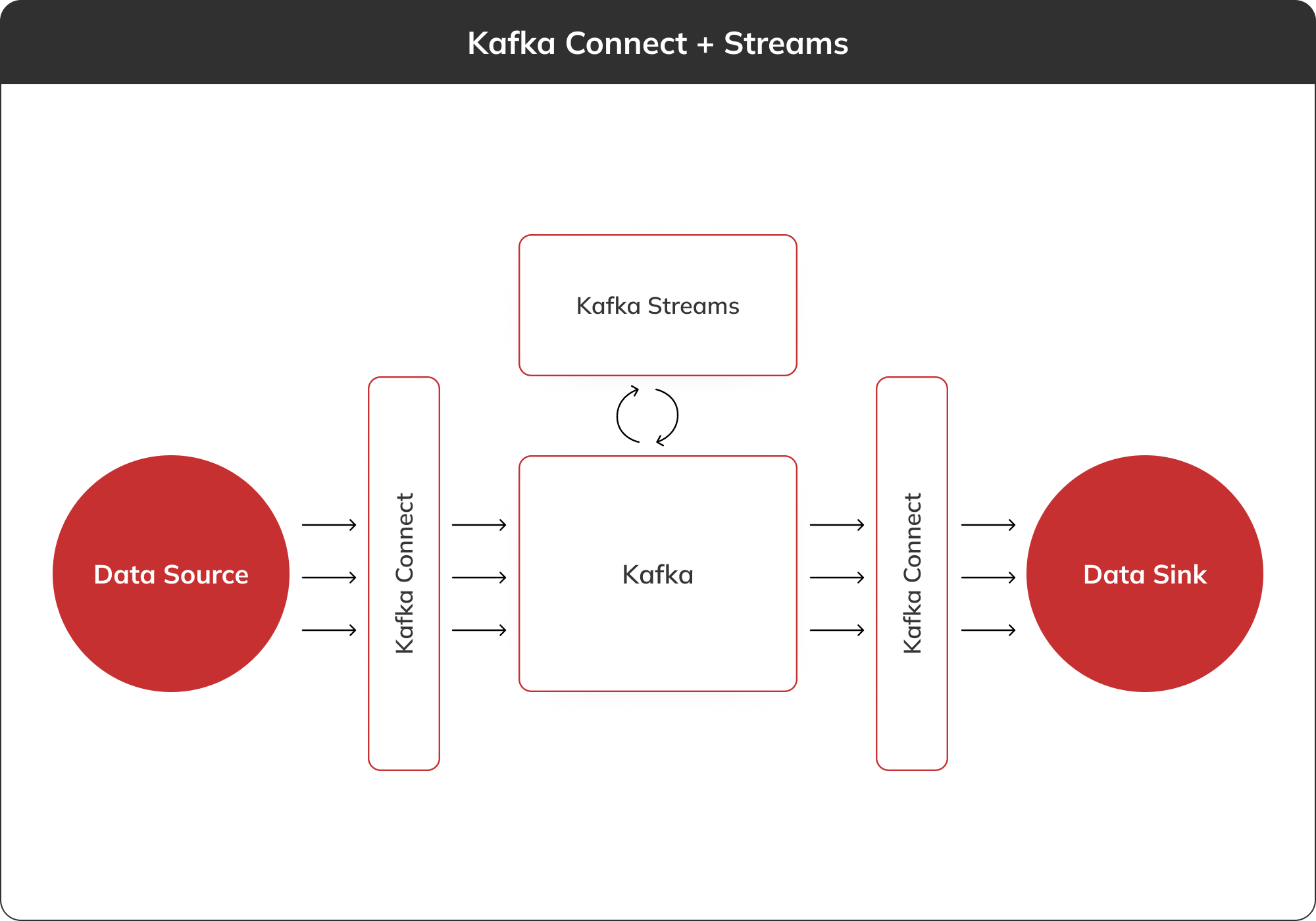
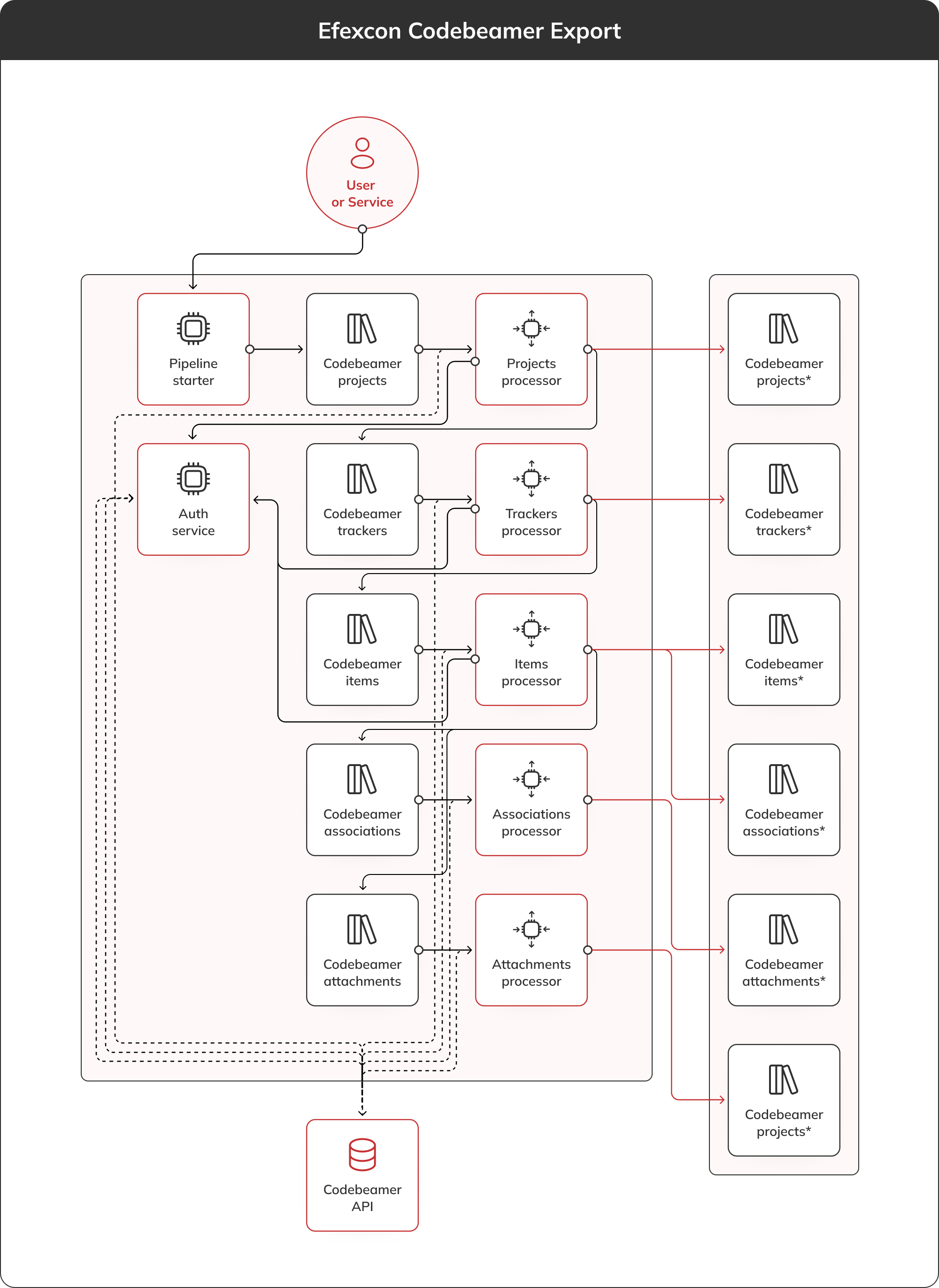
Veuillez laisser vos coordonnées, nous vous enverrons notre aperçu par e-mail.
Je consens à ce que mes données personnelles soient traitées afin d'envoyer du matériel de marketing personnalisé conformément à la directive sur la protection des données. Politique de confidentialité. En confirmant la soumission, vous acceptez de recevoir du matériel de marketing
Merci !
Le formulaire a été soumis avec succès.
Vous trouverez de plus amples informations dans votre boîte aux lettres.

Innowise est une société internationale de développement de logiciels à cycle complet fondée en 2007. Nous sommes une équipe de plus de 3000+ professionnels de l'informatique développant des logiciels pour d'autres
professionnels dans le monde entier.
Embaucher développeurs dédiés
Embaucher développeurs web
Embaucher développeurs mobiles
À propos
Services
Technologies
Secteurs
Projets
 Embaucher
Embaucher
fr Français
Sélection de la langue

Innowise est une société internationale de développement de logiciels à cycle complet fondée en 2007. Nous sommes une équipe de plus de 3000+ professionnels de l'informatique développant des logiciels pour d'autres
professionnels dans le monde entier.
Aperçu du téléchargement
Embaucher développeurs mobiles