 Nous recruter
Nous recruter


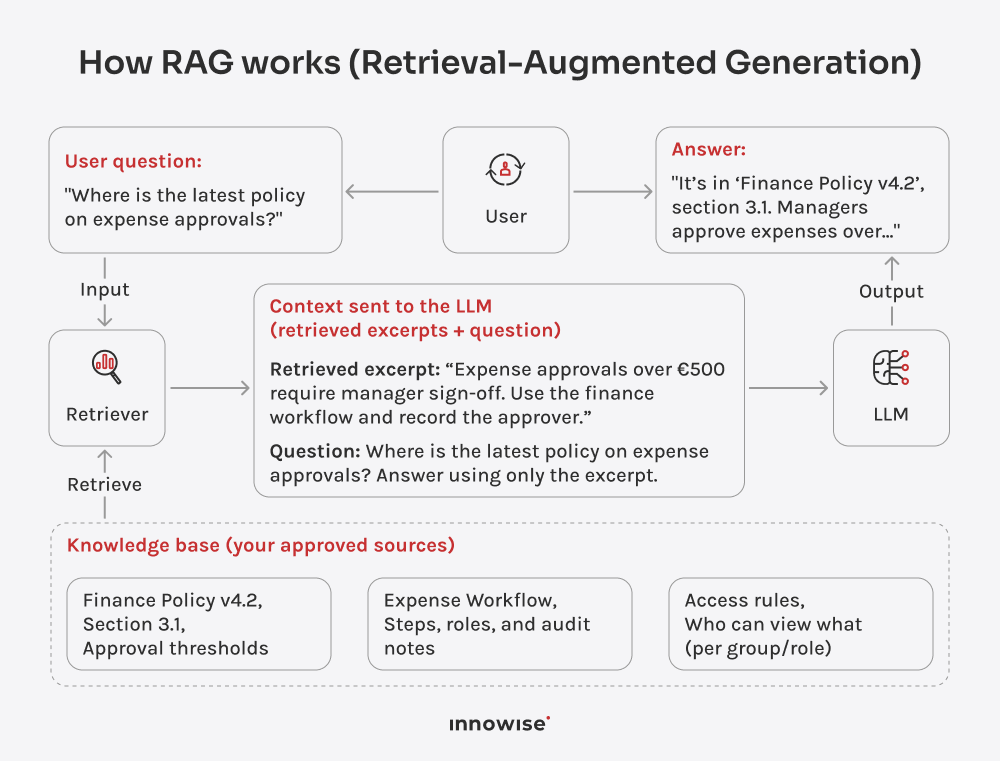
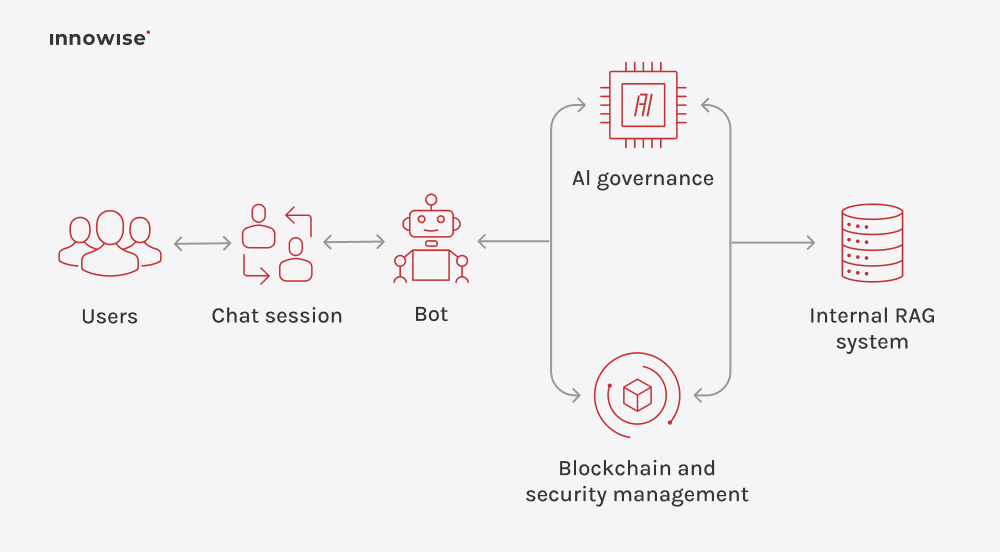
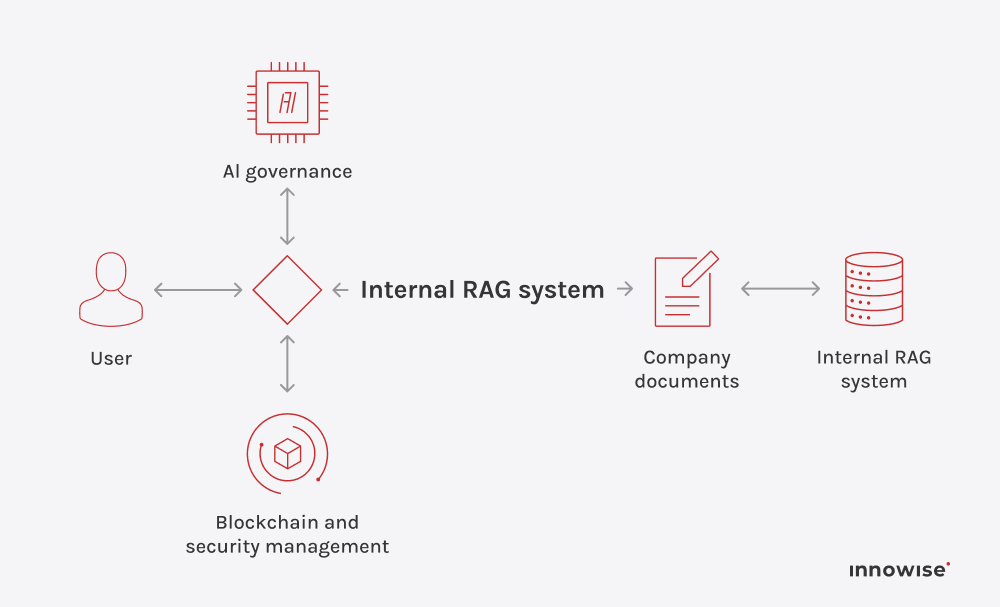
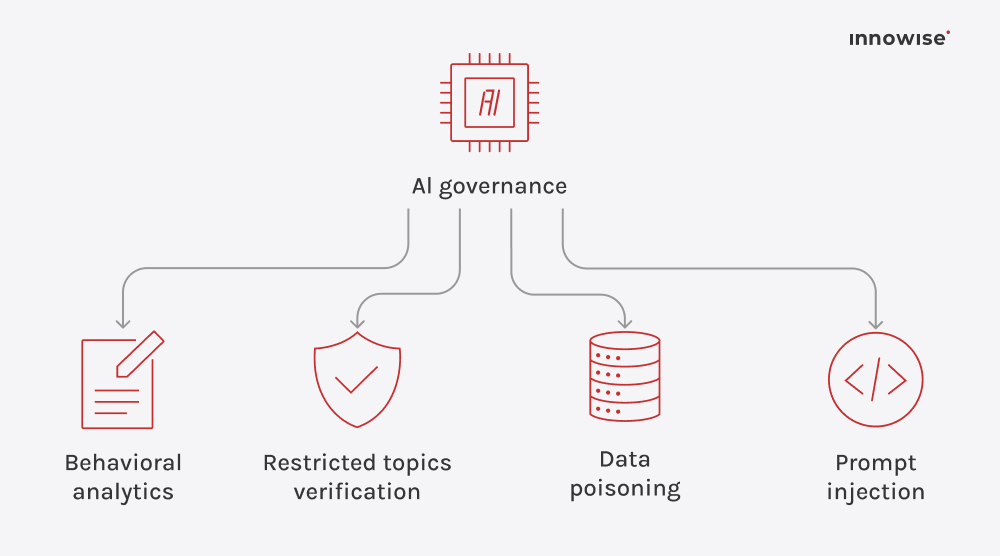


Il peut utiliser des documents internes, des articles de la base de connaissances, des pages wiki, du contenu d'assistance et d'autres sources de texte que vous approuvez. L'essentiel est que vous contrôliez les sources et les règles d'accès.












Merci !
Votre message a été envoyé.
Nous traiterons votre demande et vous contacterons dès que possible.

