 Contrátanos
Contrátanos


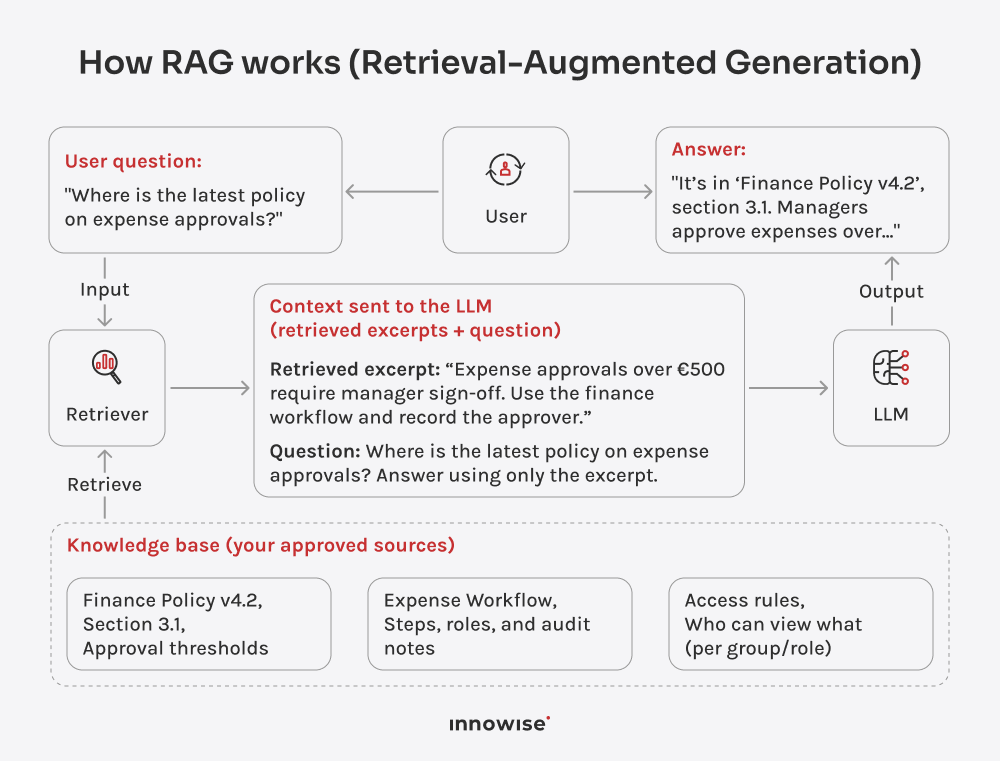
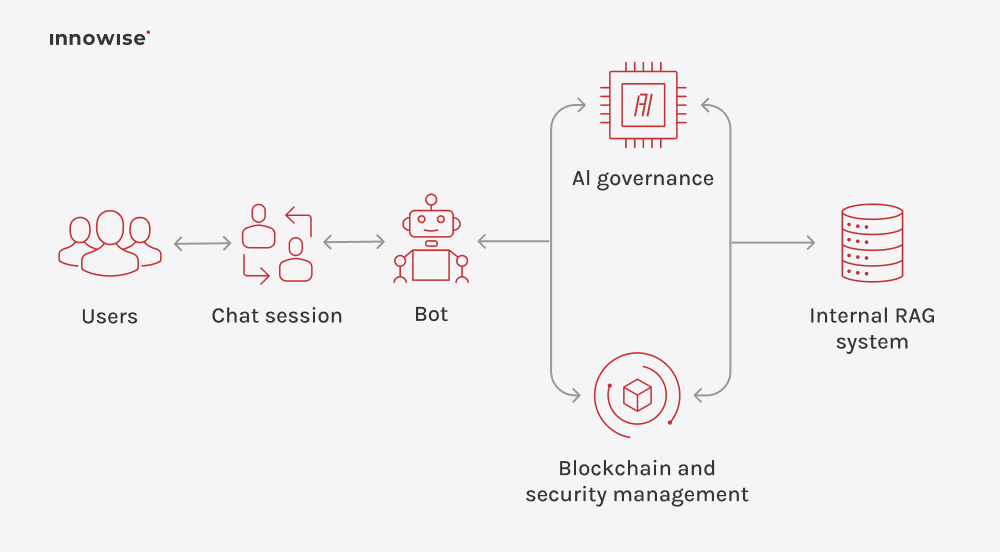
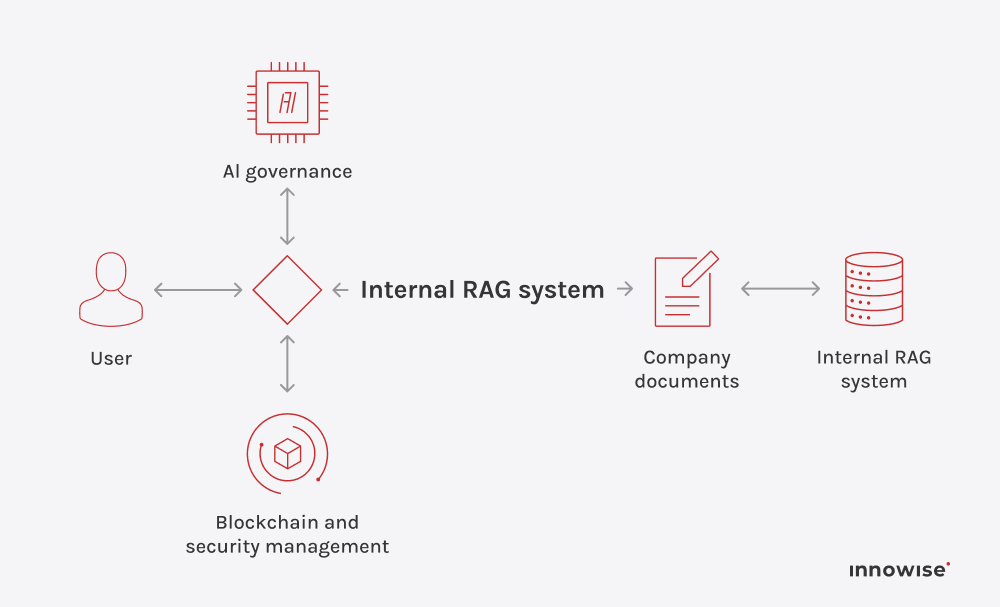
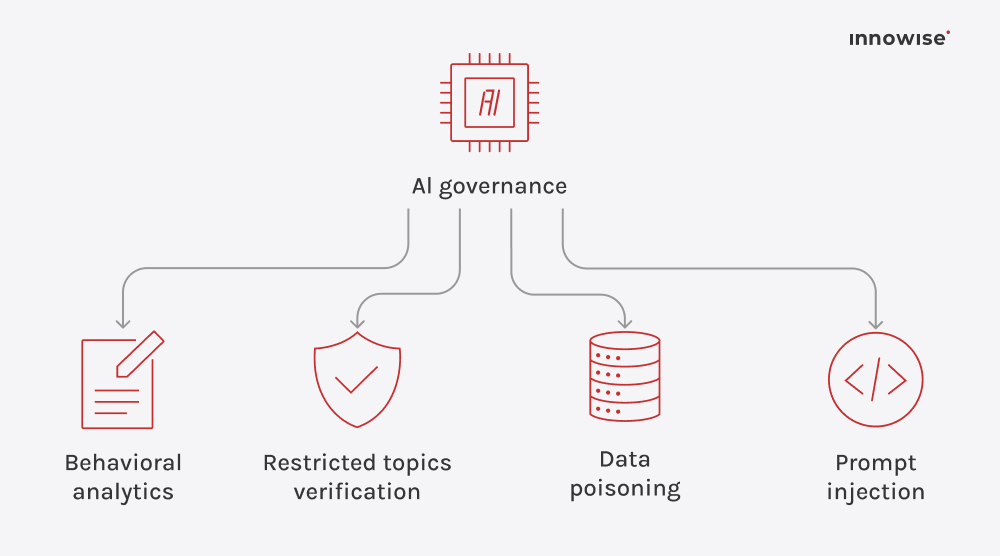


Puede utilizar documentos internos, artículos de la base de conocimientos, páginas wiki, contenidos de soporte y otras fuentes de texto que apruebe. La clave es que tú controlas las fuentes y las reglas de acceso.












Gracias.
Su mensaje ha sido enviado.
Procesaremos su solicitud y nos pondremos en contacto con usted lo antes posible.

