 Anlita oss
Anlita oss
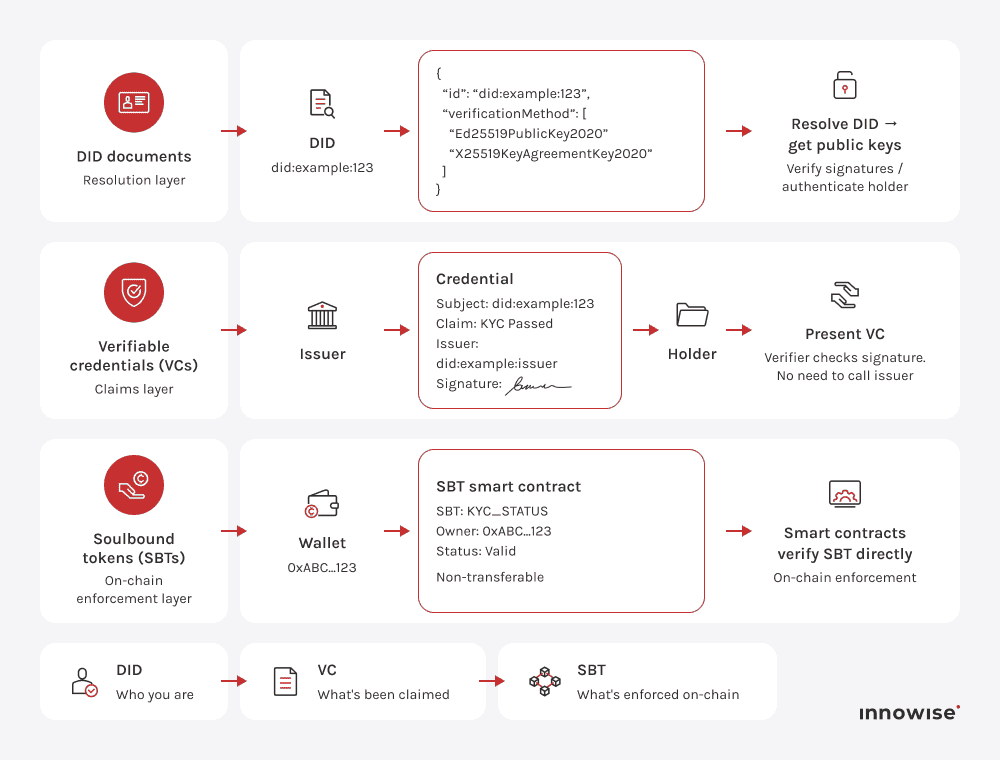




En decentraliserad identifierare är en unik, upplösbar identifierare som pekar på ett DID-dokument som innehåller publika nycklar och verifieringsmetoder. Det gör det möjligt för enheter att bevisa identitet eller kontroll utan att förlita sig på en central myndighet. I praktiken ersätter den databasuppslagningar med kryptografisk verifiering.












Tack!
Ditt meddelande har skickats.
Vi behandlar din begäran och återkommer till dig så snart som möjligt.
