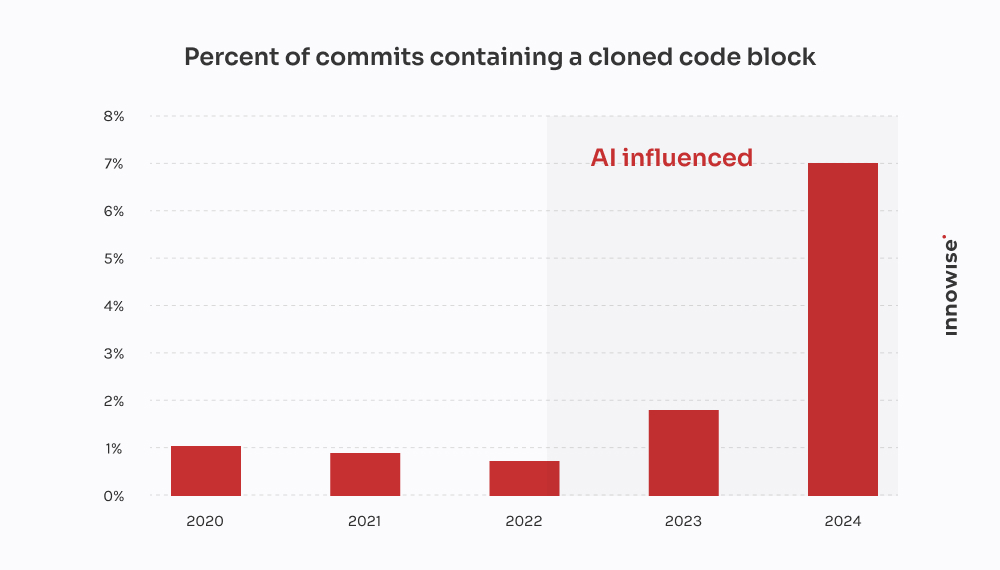
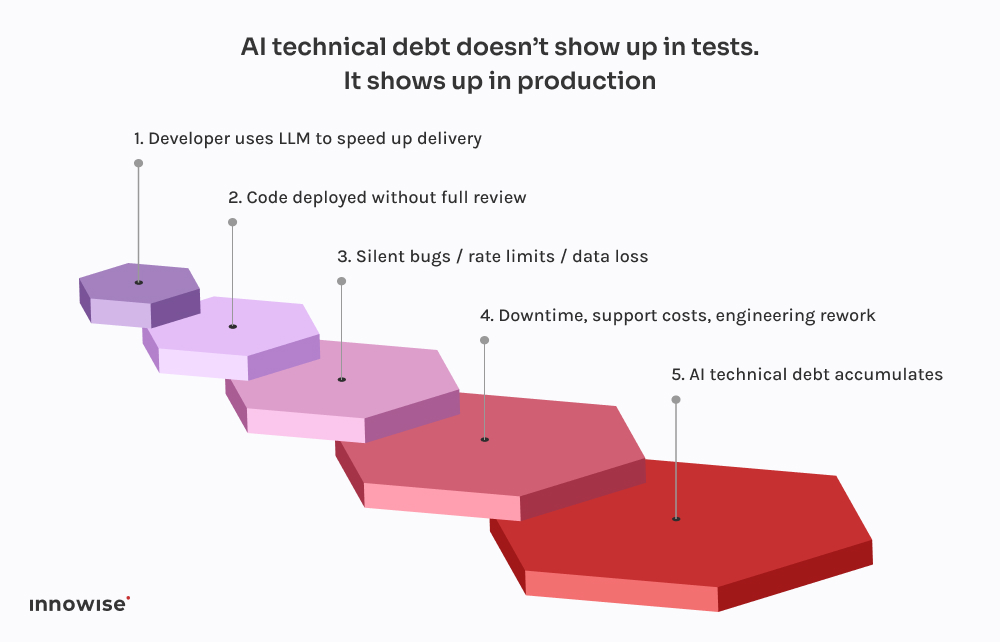
Deze kwam van een snelgroeiend fintechbedrijf.
Ze waren bezig met het uitrollen van een nieuwe versie van hun klantgegevensmodel, waarbij één groot JSONB-veld in Postgres werd opgesplitst in meerdere genormaliseerde tabellen. Vrij standaard werk. Maar met krappe deadlines en te weinig handen, besloot een van de ontwikkelaars om "de zaken te versnellen" door ChatGPT te vragen een migratiescript te genereren.
Aan de oppervlakte zag het er goed uit. Het script parste de JSON, haalde de contactinformatie eruit en voegde deze in een nieuwe user_contacts tafel.
Dus ze voerden het uit.
Geen generale repetitie. Geen back-up. Rechtstreeks naar de staging, die, zo bleek, gegevens deelde met de productie via een replica.
Een paar uur later kreeg de klantenservice e-mails. Gebruikers ontvingen geen betalingsmeldingen. Anderen hadden ontbrekende telefoonnummers in hun profiel. Toen hebben ze ons gebeld.
Wat ging er mis?
We hebben het probleem getraceerd naar het script. Het deed de basisextractie, maar het maakte drie fatale aannames:
- Het kon niet omgaan met
NULL waarden of ontbrekende sleutels in de JSON-structuur. - Het voegde gedeeltelijke records in zonder validatie.
- Het gebruikte
ON CONFLICT DO NOTHING, dus alle mislukte invoegingen werden stilzwijgend genegeerd.
Resultaat: over 18% van de contactgegevens was verloren gegaan of beschadigd. Geen logboeken. Geen foutmeldingen. Gewoon stil gegevensverlies.
Wat er nodig was om te repareren
We stelden een klein team samen om de rommel te ontwarren. Dit is wat we deden:
- Diagnose en replicatie (4 uur) We hebben het script opnieuw gemaakt in een sandboxomgeving en het uitgevoerd tegen een snapshot van de database. Zo bevestigden we het probleem en brachten we precies in kaart wat er ontbrak.
- Forensische gegevenscontrole (8 uur) We vergeleken de kapotte staat met back-ups, identificeerden alle records met ontbrekende of gedeeltelijke gegevens en vergeleken ze met gebeurtenislogboeken om te achterhalen welke invoegingen mislukten en waarom.
- De migratielogica herschrijven (12 uur) We herschreven het hele script in Python, voegden volledige validatielogica toe, bouwden een rollbackmechanisme en integreerden het in de CI-pijplijn van de klant. Deze keer bevatte het tests en ondersteuning voor dry-run.
- Handmatig gegevensherstel (6 uur) Sommige records waren niet terug te halen uit back-ups. We haalden de ontbrekende velden uit externe systemen (hun CRM en e-mail API's) en herstelden de rest handmatig.
Totale tijd: 30 technische uren
Twee ingenieurs, drie dagen. Kosten voor de klant: ongeveer $4,500 aan servicekosten.
Maar de grootste klap kwam van de gevolgen voor klanten. Mislukte meldingen leidden tot gemiste betalingen en churn. De klant vertelde ons dat ze minstens $10,000 aan supporttickets, SLA-compensatie en goodwillcredits voor dat ene mislukte script.
Het ironische is dat een senior ontwikkelaar de juiste migratie in misschien vier uur had kunnen schrijven. Maar de belofte van AI snelheid kostte hen uiteindelijk twee weken schoonmaakwerk en reputatieschade.
 Inhuren
Inhuren