 Inhuren
Inhuren



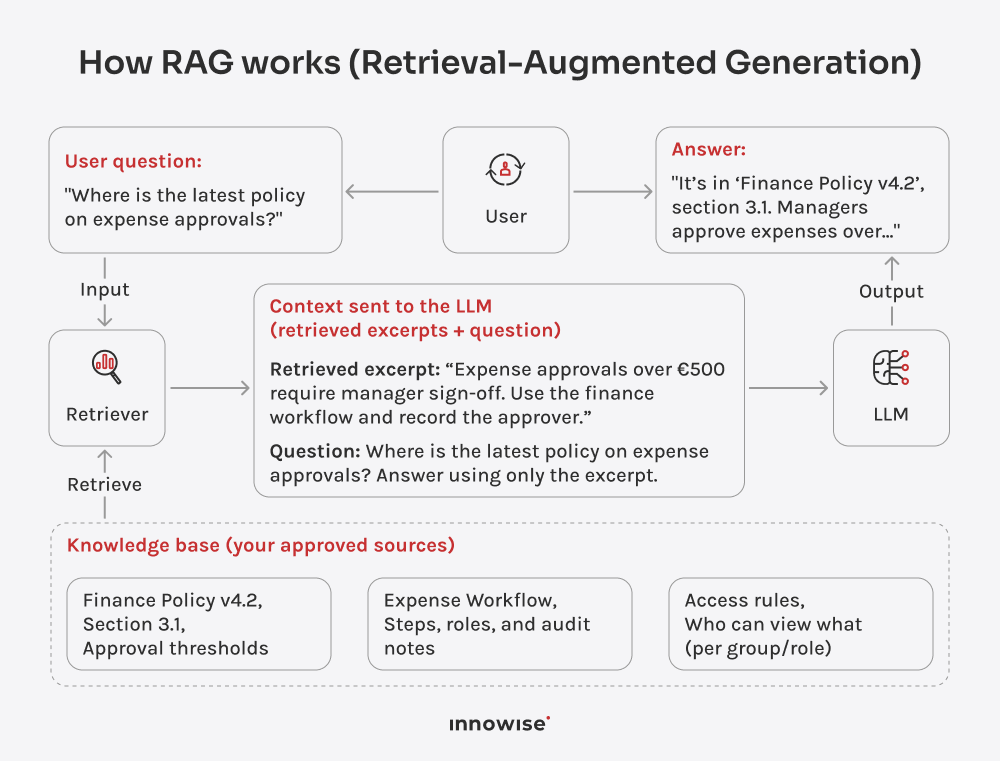
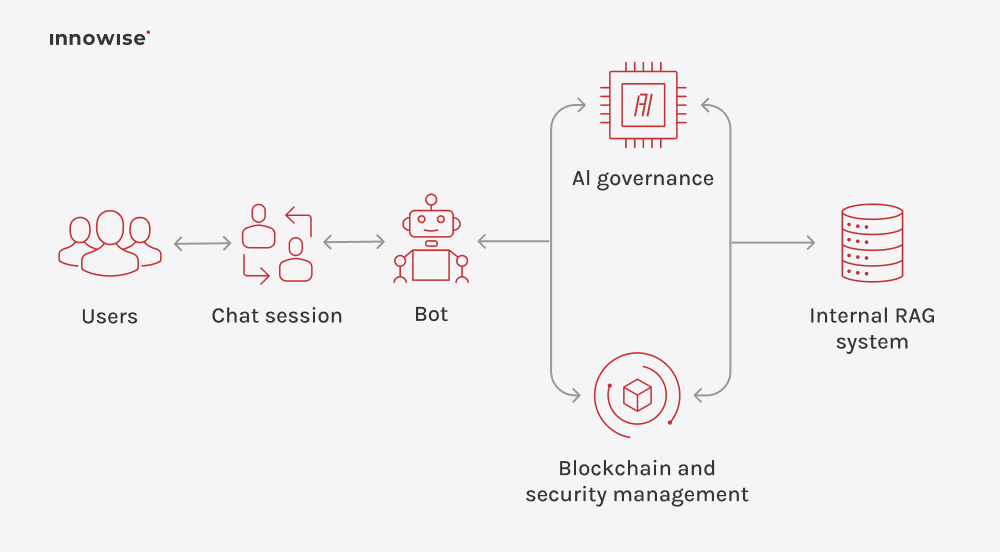
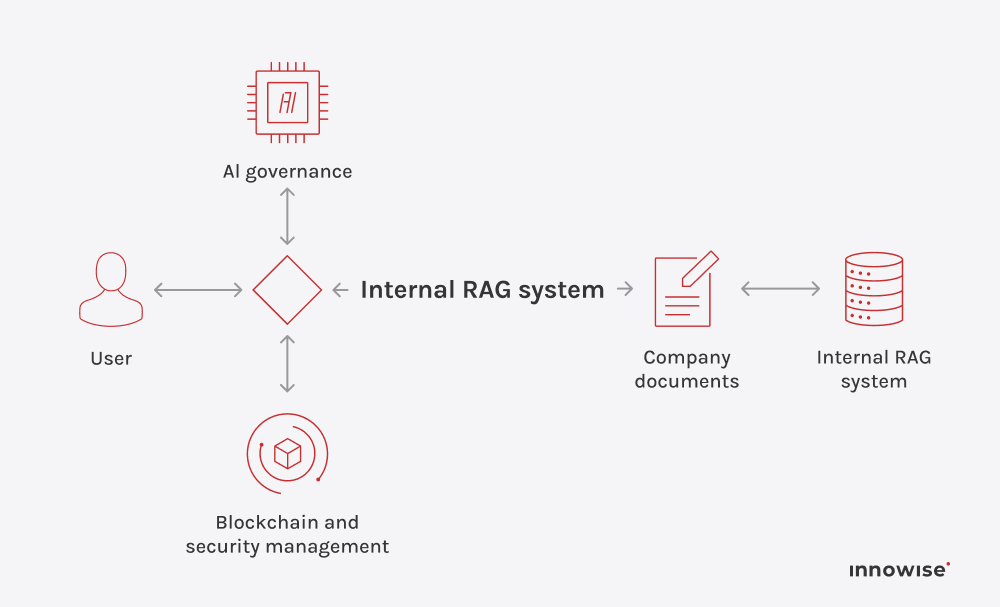
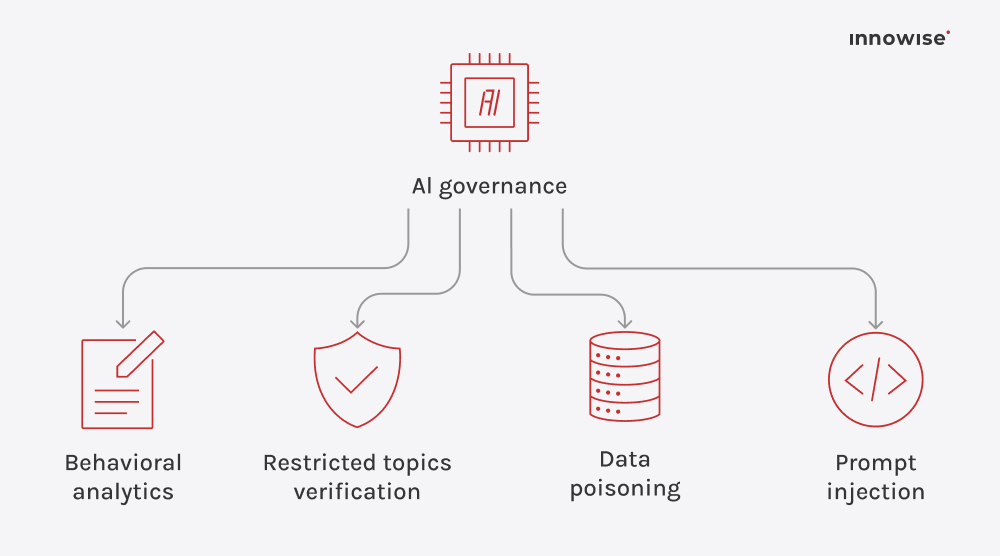


Het kan interne documenten, kennisbankartikelen, wikipagina's, ondersteuningscontent en andere tekstbronnen gebruiken die u goedkeurt. Het belangrijkste is dat u de bronnen en de toegangsregels beheert.














Bedankt.
Uw bericht is verzonden.
We verwerken je aanvraag en nemen zo snel mogelijk contact met je op.
