 Assumeteci
Assumeteci


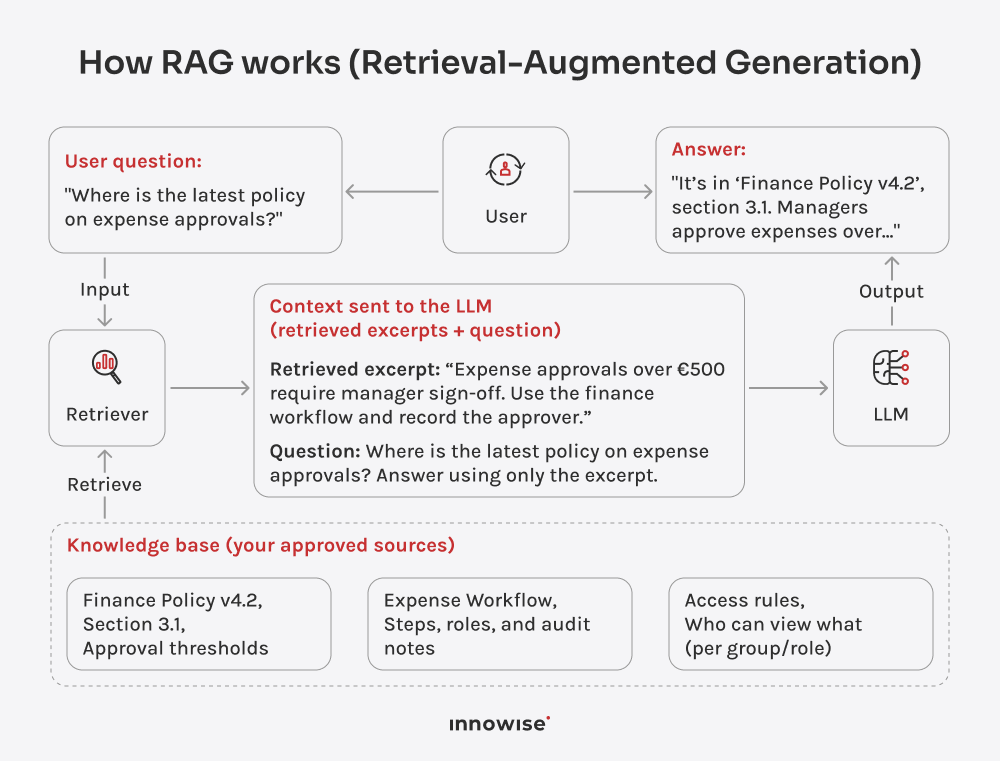
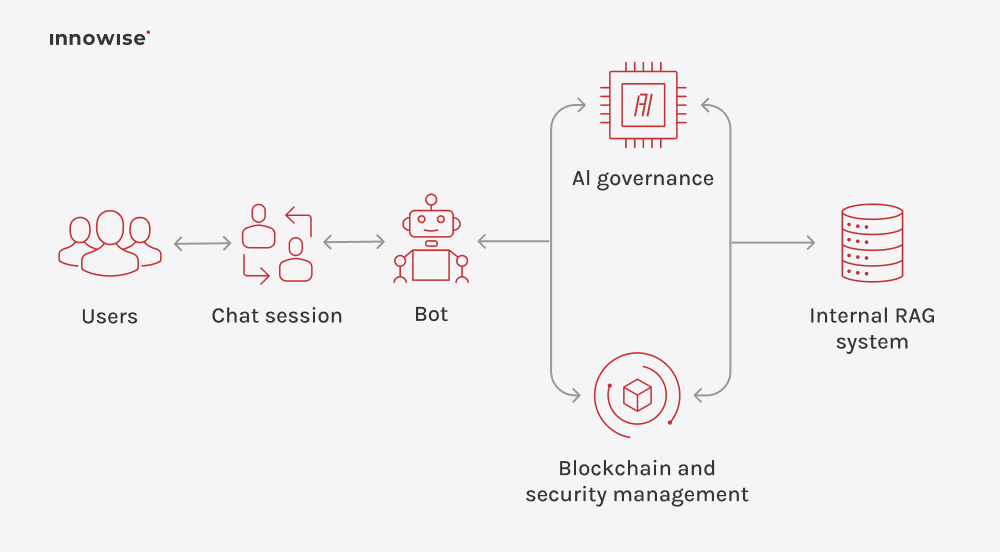
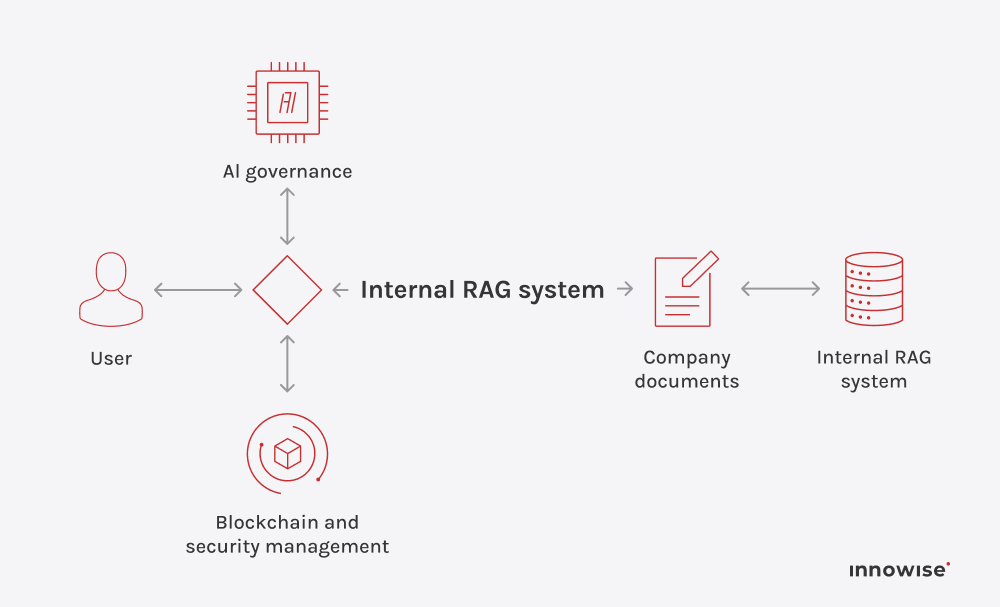
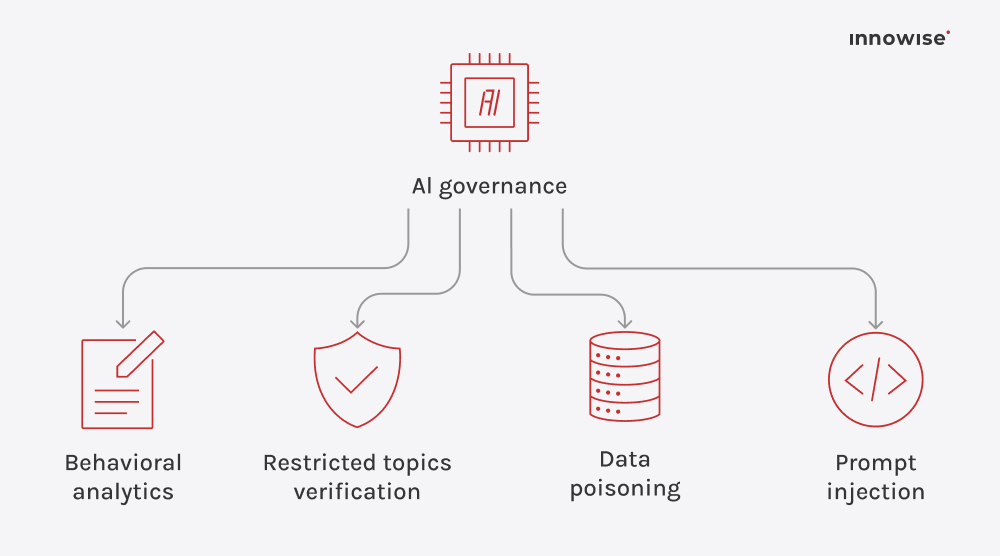


Può utilizzare documenti interni, articoli della knowledge base, pagine wiki, contenuti di supporto e altre fonti di testo approvate dall'azienda. L'importante è che siate voi a controllare le fonti e le regole di accesso.












Grazie!
Il tuo messaggio è stato inviato.
Elaboreremo la vostra richiesta e vi ricontatteremo al più presto.

