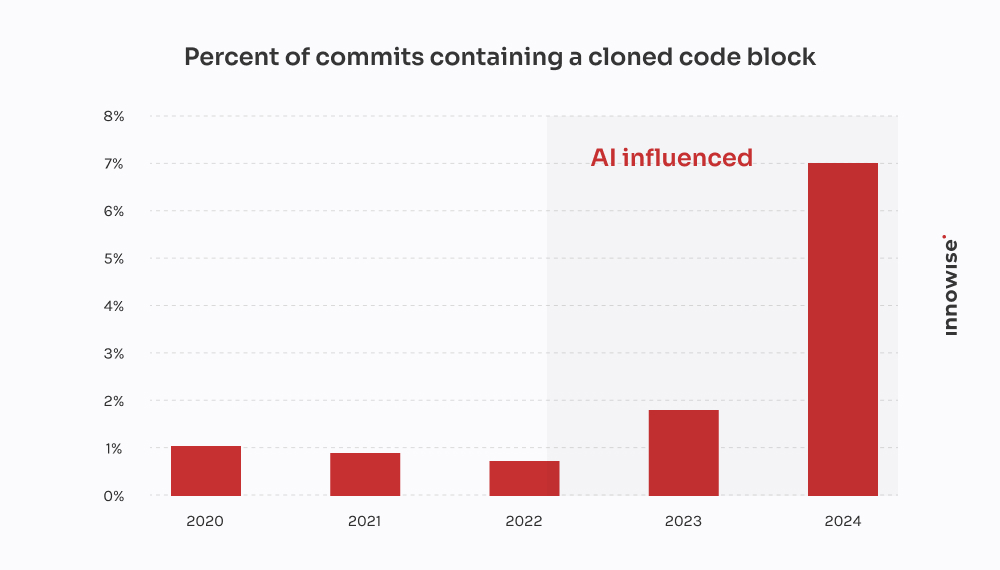
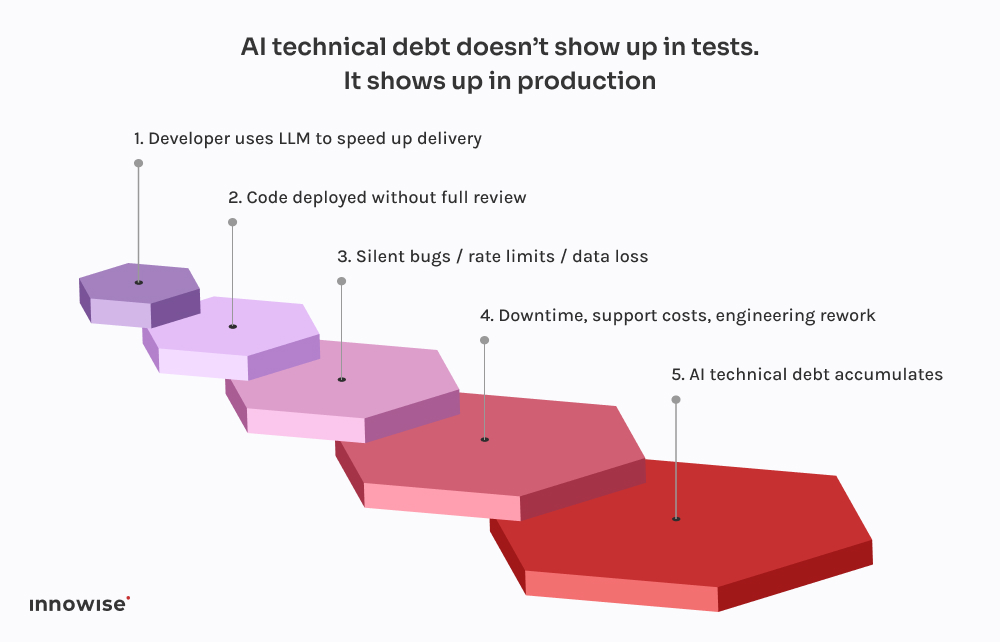
Este vino de una empresa de tecnología financiera de rápido crecimiento.
Estaban desplegando una nueva versión de su modelo de datos de clientes, dividiendo un gran campo JSONB en Postgres en múltiples tablas normalizadas. Algo bastante estándar. Pero con plazos ajustados y pocas manos, uno de los desarrolladores decidió "acelerar las cosas" pidiendo a ChatGPT que generara un script de migración.
A primera vista tenía buena pinta. El script analizaba el JSON, extraía la información de contacto y la insertaba en un nuevo archivo user_contacts mesa.
Así que lo ejecutaron.
Sin simulacro. Sin copia de seguridad. Directamente a la puesta en escena, que, como resulta, estaba compartiendo datos con la producción a través de una réplica.
Unas horas más tarde, el servicio de atención al cliente empezó a recibir correos electrónicos. Los usuarios no recibían notificaciones de pago. A otros les faltaban números de teléfono en sus perfiles. Fue entonces cuando nos llamaron.
Qué salió mal
Rastreamos el problema hasta el script. Hizo la extracción básica, pero hizo tres suposiciones fatales:
- No manejaba
NULL o claves que faltan dentro de la estructura JSON. - Insertaba registros parciales sin validación.
- Utilizaba
ON CONFLICT DO NOTHING, por lo que cualquier inserción fallida se ignoraba silenciosamente.
Resultado: sobre 18% de los datos de contacto se perdió o se corrompió. No hay registros. No hay mensajes de error. Sólo pérdida de datos silenciosa.
Lo que costó arreglar
Asignamos un pequeño equipo para desenredar el embrollo. Esto es lo que hicimos:
- Diagnóstico y replicación (4 horas) Volvimos a crear el script en un entorno aislado y lo ejecutamos contra una instantánea de la base de datos. Así confirmamos el problema y localizamos exactamente lo que faltaba.
- Auditoría forense de datos (8 horas) Comparamos el estado roto con las copias de seguridad, identificamos todos los registros con datos faltantes o parciales y los cotejamos con los registros de eventos para rastrear qué inserciones fallaron y por qué.
- Reescribir la lógica de migración (12 horas) Volvimos a escribir todo el script en Python, añadimos una lógica de validación completa, creamos un mecanismo de reversión y lo integramos en el proceso CI del cliente. Esta vez, incluía pruebas y soporte de ejecución en seco.
- Recuperación manual de datos (6 horas) Algunos registros no se podían recuperar de las copias de seguridad. Extrajimos los campos que faltaban de sistemas externos (sus API de CRM y proveedor de correo electrónico) y restauramos manualmente el resto.
Tiempo total: 30 horas de ingeniería
Dos ingenieros, tres días. Coste para el cliente: unos $4,500 en comisiones de servicio.
Pero el golpe más duro lo recibieron los clientes. Las notificaciones fallidas provocaron impagos y bajas. El cliente nos dijo que gastó al menos $10,000 en tickets de soporte, compensaciones de SLA y créditos de buena voluntad por ese script chapucero.
Lo irónico es que un desarrollador experimentado podría haber escrito la migración correcta en unas cuatro horas. Pero la promesa de velocidad AI acabó costándoles dos semanas de limpieza y daños a su reputación.
 Contrátanos
Contrátanos