Dieser kam von einem schnell wachsenden Fintech-Unternehmen.
Sie waren dabei, eine neue Version ihres Kundendatenmodells einzuführen, wobei ein großes JSONB-Feld in Postgres in mehrere normalisierte Tabellen aufgeteilt wurde. Ziemlich normales Zeug. Aber angesichts der knappen Fristen und des Mangels an Mitarbeitern beschloss einer der Entwickler, die Dinge zu "beschleunigen", indem er ChatGPT bat, ein Migrationsskript zu erstellen.
Oberflächlich betrachtet sah es gut aus. Das Skript analysierte das JSON, extrahierte die Kontaktinformationen und fügte sie in eine neue user_contacts Tisch.
Also haben sie es durchgeführt.
Kein Probelauf. Kein Backup. Direkt ins Staging, das, wie sich herausstellte, die Daten über eine Replik mit der Produktion teilte.
Ein paar Stunden später erhielt der Kundendienst E-Mails. Die Nutzer erhielten keine Zahlungsbenachrichtigungen. Bei anderen fehlten Telefonnummern in ihren Profilen. Daraufhin riefen sie uns an.
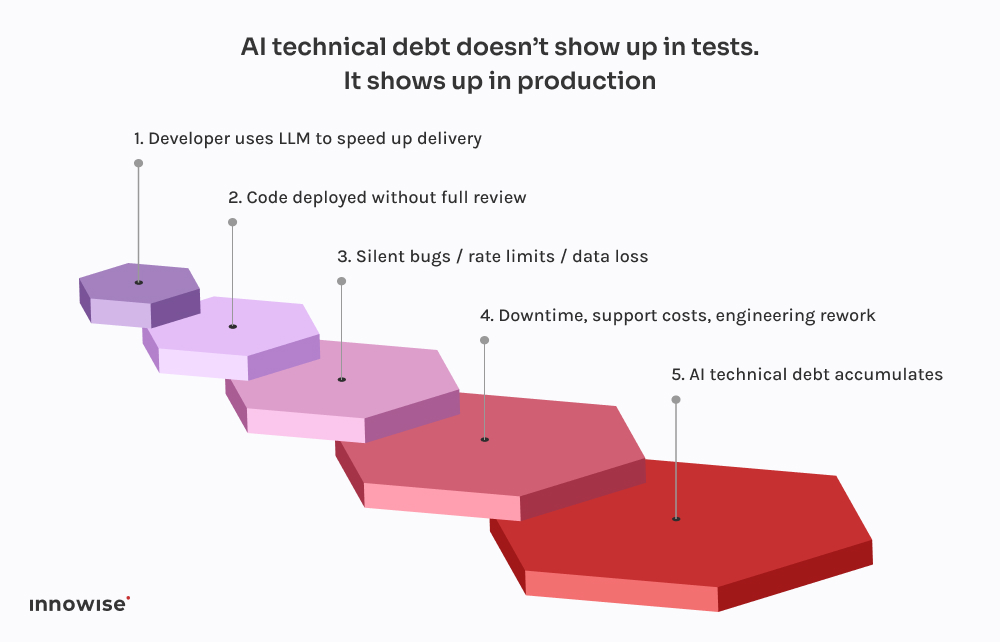
Was schief gelaufen ist
Wir haben das Problem auf das Skript zurückgeführt. Es führte die grundlegende Extraktion durch, machte aber drei fatale Annahmen:
- Es hat nicht gehandelt
NULL Werte oder fehlende Schlüssel innerhalb der JSON-Struktur. - Es wurden partielle Datensätze ohne Überprüfung eingefügt.
- Es verwendet
ON CONFLICT DO NOTHING, so dass alle fehlgeschlagenen Einfügungen stillschweigend ignoriert wurden.
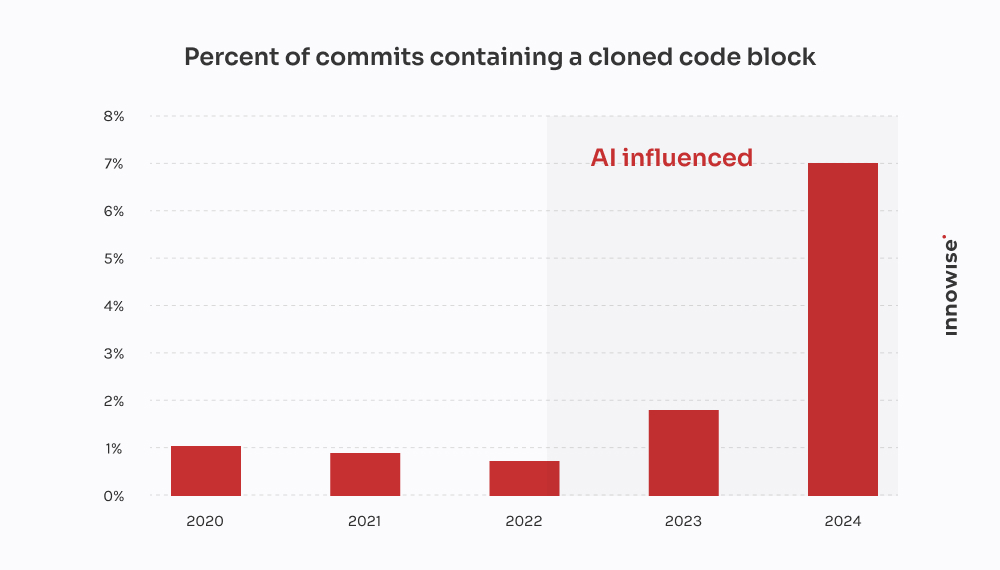
Ergebnis: über 18% der Kontaktdaten entweder verloren gegangen oder beschädigt worden ist. Keine Protokolle. Keine Fehlermeldungen. Nur stiller Datenverlust.
Was es brauchte, um die
Wir haben ein kleines Team damit beauftragt, das Durcheinander zu entwirren. Das haben wir getan:
- Diagnose und Replikation (4 Stunden) Wir erstellten das Skript in einer Sandbox-Umgebung neu und führten es mit einem Snapshot der Datenbank aus. Auf diese Weise konnten wir das Problem bestätigen und genau zuordnen, was fehlte.
- Forensische Datenprüfung (8 Stunden) Wir verglichen den defekten Zustand mit Backups, identifizierten alle Datensätze mit fehlenden oder unvollständigen Daten und glichen sie mit Ereignisprotokollen ab, um festzustellen, welche Einfügungen fehlgeschlagen sind und warum.
- Neuschreiben der Migrationslogik (12 Stunden) Wir schrieben das gesamte Skript in Python neu, fügten eine vollständige Validierungslogik hinzu, bauten einen Rollback-Mechanismus und integrierten es in die CI-Pipeline des Kunden. Diesmal mit Tests und Unterstützung für Trockenübungen.
- Manuelle Datenwiederherstellung (6 Stunden) Einige Datensätze konnten aus den Backups nicht wiederhergestellt werden. Wir zogen fehlende Felder aus externen Systemen (CRM- und E-Mail-Anbieter-APIs) und stellten den Rest manuell wieder her.
Gesamtzeit: 30 Ingenieurstunden
Zwei Ingenieure, drei Tage. Kosten für den Kunden: etwa $4,500 an Dienstleistungsgebühren.
Der größere Schaden entstand jedoch durch die Kundenabwanderung. Fehlgeschlagene Benachrichtigungen führten zu verpassten Zahlungen und Abwanderung. Der Kunde sagte uns, er habe mindestens $10,000 für Support-Tickets, SLA-Entschädigungen und Goodwill-Gutschriften wegen dieses einen verpfuschten Skripts.
Das Ironische daran ist, dass ein erfahrener Entwickler die korrekte Migration in vielleicht vier Stunden hätte schreiben können. Aber das Versprechen von AI-Geschwindigkeit kostete sie am Ende zwei Wochen Aufräumarbeiten und Rufschädigung.
 Einstellen
Einstellen