Lämna dina kontaktuppgifter, så skickar vi dig vår översikt via e-post
Jag samtycker till att mina personuppgifter behandlas för att skicka personligt marknadsföringsmaterial i enlighet med Integritetspolicy. Genom att bekräfta inlämningen samtycker du till att få marknadsföringsmaterial
Tack!
Formuläret har skickats in framgångsrikt. Ytterligare information finns i din brevlåda.
Innowise är ett internationellt företag för utveckling av programvara med full cykel som grundades 2007. Vi är ett team av IT-proffs som utvecklar programvara för andra proffs över hela världen.
Innowise är ett internationellt företag för utveckling av programvara med full cykel som grundades 2007. Vi är ett team av IT-proffs som utvecklar programvara för andra proffs över hela världen.
AI omformar dataprocesser: automatisera tråkiga uppgifter som rengöring, omvandling och generering av data, vilket frigör team som kan fokusera på insikter och strategi.
Dataarkitekturen utvecklas snabbt: Decentraliserade modeller (som Data Mesh) och enhetliga system (som Data Fabric) gör datahanteringen mer flexibel och skalbar än någonsin.
Insikter i realtid är nu en nödvändighet: Företag måste bearbeta och agera på data när de kommer in för att förbli konkurrenskraftiga och kunna reagera på omedelbara möjligheter eller risker.
Moln strategierna är diversifierade: Hybrid- och multi-moln-miljöer ger företagen den flexibilitet de behöver, men de kräver också robust styrning för att hantera komplexitet och kostnader.
Data är inte längre bara till för analytiker: Självbetjäningsverktyg, intuitiva visualiseringar och automatiserade insikter gör det möjligt för icke-tekniska team att fatta datadrivna beslut. En sådan datademokratisering förändrar verksamheten i hela företaget.
Låt mig börja med ett djärvt påstående: 2026är räkneåret för de stora Dataindustrin. Vi har tillbringat det senaste decenniet med att experimentera med all ny teknik som finns: AI, IoT, molnplattformar och alla dessa buzzwords. Men vet du vad? Det är dags att ställa upp eller så missar du båten. Om ditt företag inte redan funderar på hur man ska omvandla den enorma mängden data till något användbart, kommer du att hamna i skymundan.
2026 är det dags att få dessa verktyg att fungera för dig och ligga steget före. Är du nyfiken på vilka trender du ska hålla koll på? Låt oss dyka in.
Topp 15 + trender för stora datamängder som formar 2026
År 2026, När big data blir en viktig drivkraft för affärsvärde påverkar det alla branscher där ute. Från AI-drivna analytiska copiloter till edge processing i realtid - dessa trender definierar big data framtid som redan håller på att utvecklas. De kommer att forma din affärsframgång, så läs den här artikeln till slutet.
1. Generativ AI för datateknik och analys
En av de mest inflytelserika framtida trender inom analys av stora datamängder är ökningen av Generative AI. Även om det inte är perfekt ännu, hanterar GenAI redan de mest tidskrävande och tråkiga delarna av datateknik. AI kommer inte att eliminera datakvalitetsutmaningar helt, men det kan avsevärt minska de timmar som ditt team spenderar på dataförberedelse.
AI bäddas nu in i datapipelines och kan automatisera uppgifter som datarengöring, fylla i saknade luckor (imputation) och omvandla data. Detta innebär att du får rena, färdiga data på en bråkdel av tiden. Till exempel plattformar som Databricks och Snowflake innehåller redan inbyggd funktionalitet för generativa-AI-aktiverade pipelines. Det hjälper organisationer att automatisera datatransformation, fylla luckor och leverera AI-klara dataset.
Proffstips:
Börja integrera AI-verktyg i dina datapipelines för att automatisera rengöring och omvandling.
Investera i plattformar med generativa AI funktioner för att fylla dataluckor och förbättra noggrannheten.
Uppmuntra ditt datateam att fokusera på strategisk analys och använda AI-drivna insikter för att fatta snabbare beslut.
Kontinuerligt övervaka AI-utdata för att säkerställa datakvalitet och anpassa dem till affärsmål.
Låt oss utforska hur data kan lösa dina affärsutmaningar
2. Data Mesh + Data Fabric för att bygga upp ryggraden i dataarkitekturen
Att förlita sig på föråldrade dataarkitekturer kommer att hålla dig tillbaka. Nyckeln till att förbli konkurrenskraftig är att använda Data Mesh och Data Fabric.
Data Mesh decentraliserar ägandet av data och låter domänteam hantera och servera sina egna data, vilket eliminerar flaskhalsar i den centrala IT-organisationen. Data Fabric kopplar samman alla datakällor (moln, on-prem, edge) till ett sammanhängande system med automatiserade metadata, lineage och integration. Tillsammans skapar de en skalbar, flexibel arkitektur som möjliggör flexibilitet utan att ge avkall på kontrollen.
För att få detta att fungera måste du börja med att identifiera viktiga domäner inom ditt företag som kan ta ansvar för sina egna data.
Implementera ett metadataskikt som säkerställer att alla data är sökbara, kompatibla och lätta att hantera.
Investera i verktyg och utbildning för att hjälpa domänteamen att fullt ut anamma äganderätten till data och undvika kaos.
Viktigast av allt är att fokusera på att främja en kultur där data behandlas som en produkt, med tydligt ägarskap och samarbete.
Medan Data Mesh definierar arkitektur decentralisering fungerar bäst när den kombineras med ett “data-som-produkt”-tänk, där varje dataset ägs, dokumenteras och hanteras som en riktig produkt.
3. Data som en produkt
Data Mesh ger dig strukturen. Data as a Product ger dig disciplin. I 2026, smarta företag inte bara decentraliserar data, de hanterar dem som en produkt, med tydligt ägande, dokumentation och mätbart värde. Många företag arbetar fortfarande med att centralisera sina data, men trenden går snabbt bort från data som ligger begravda i slumpmässiga kalkylblad eller isolerade databaser. I ett data-som-produkt-tänk har varje dataset dokumentation, rolltilldelning, servicenivåavtal och en återkopplingsslinga för förbättringar.
På så sätt vet marknadsavdelningen var deras kampanjdata finns. Ekonomiavdelningen litar på intäktssiffrorna utan att behöva en “dataavstämningsdag”. Och ingenjörsavdelningen slutar äntligen att fungera som flaskhalsen mellan alla andras instrumentpaneler.
Plattformar som Snowflake Data Moln och Databricks marknadsplats hjälper redan team att publicera, dela och till och med tjäna pengar på dataprodukter internt eller med partners. Det öppnar nya dörrar för samarbete och nya intäktsströmmar. Särskilt när din “dataprodukt” blir något som andra vill köpa eller bygga vidare på.
Proffstips:
Tilldela tydligt ägandeskap för varje större dataset, precis som du skulle göra för en produktfunktion.
Definiera vem som ansvarar för kvalitet, dokumentation och drifttid.
Standardisera format och skapa upptäckbarhet - en intern katalog där teamen kan “shoppa” efter dataset i stället för att be Slack om länkar.
Slutligen kan du börja spåra ROI för datatillgångar: vilka som genererar insikter, besparingar eller intäkter.
"På Innowise ser vi alltid till att data fungerar för dig på ett sätt som är praktiskt och effektivt. Vårt tillvägagångssätt integrerar AI, automatiserar dataarbetsflöden och möjliggör insikter i realtid, så att ditt team inte hindras av komplexitet. Du får rena, användbara data när du behöver dem, så att du kan fatta beslut baserade på fakta."
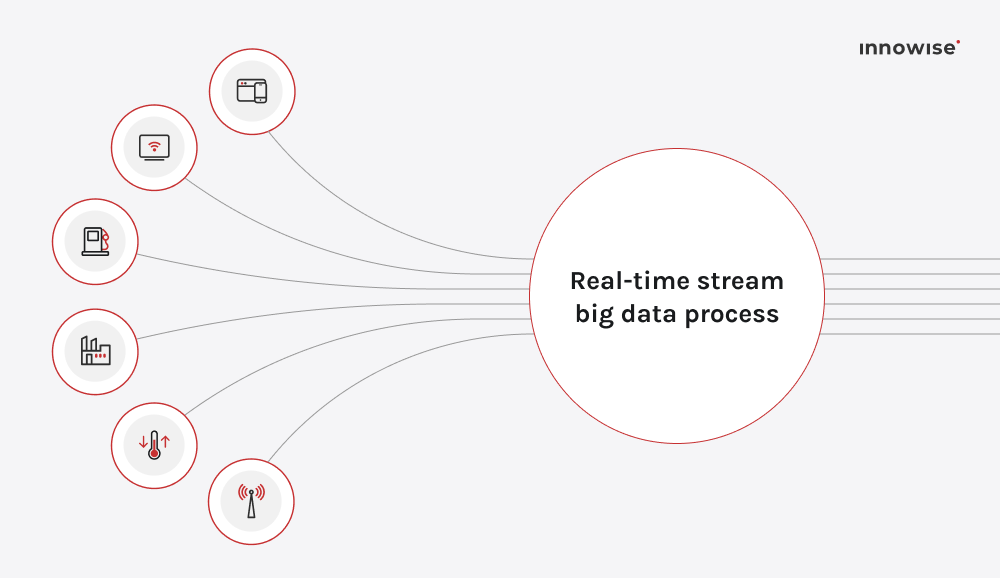
4. Realtids- och streaminganalys för stora datamängder
Nästa på listan över framtida trender inom big data ärrealtidsanalys. Konceptet har varit under utveckling i flera år, men 2026 kommer det snabbt att utvecklas från en konkurrensfördel till en grundläggande nödvändighet för organisationer som kräver omedelbara insikter. När du bearbetar data i samma ögonblick som den kommer in, istället för att vänta på batcher, får du möjlighet att agera på händelser, signaler och mönster när de händer. För big data-arenan innebär detta strömmande datakällor med stora volymer (IoT-sensorer, användarinteraktioner, loggar) genom pipelines som analyserar och svarar inom sekunder eller millisekunder.
Marknaden stöder detta skifte. Den globala sektorn för streaminganalys värderades till $23,4 miljarder år 2023 och förväntas växa till cirka $ 128,4 miljarder år 2030, med en genomsnittlig årlig tillväxttakt på cirka 28,3% mellan 2024 och 2030.Branscher som finans, telekom, tillverkning och detaljhandel använder redan strömbaserade modeller för att upptäcka bedrägerier, dynamisk prissättning, prediktivt underhåll och optimering av kundupplevelsen.
Proffstips:
Identifiera ett eller två användningsfall med stor påverkan där förseningar kostar pengar eller konkurrensfördelar (t.ex. lagerförändringar, bedrägerier, fel på utrustning).
Implementera ett proof-of-concept för strömmande analys med hjälp av tekniker som Apache Kafka, Flink eller hanterade tjänster från molnleverantörer.
Säkerställ att din arkitektur är byggd för kontinuerligt intag och utvärdering, inklusive varningar, instrumentpaneler och automatiska utlösare.
Upprätta SLA:er för styrning, datakvalitet och latens för dessa flöden, eftersom hastighet endast ger värde om insikterna är pålitliga och användbara.
Om din datastrategi fortfarande behandlar realtid som något “extra” och fokuserar starkt på batch first, 2026 kommer att belysa gapet, tro mig.
5. Grafanalys och kunskapsgrafer för att avslöja dolda relationer
Grafanalys hamnar i rampljuset 2026, inte som en ny teknik, utan för att införandet av den påskyndas snabbt av integrationen med AI. I stället för att behandla data enbart som rader och kolumner använder organisationer grafer för att förstå hur enheter hänger ihop: kunder, produkter, sensornoder, bedrägeriringar, allt möjligt. Kunskapsgrafer och grafdatabaser gör detta möjligt: de kartlägger komplexa relationer och avslöjar insikter som traditionella metoder har svårt att avslöja. Till exempel kan en senaste grafdatabasrapporten från Verified Market Reports förklarar att grafdatabaser nu är avgörande för realtidsbearbetning, semantiska relationer och AI-driven anomalidetektering.
För företagsledare är den viktigaste fördelen följande: du avslöjar Varför saker händer, inte bara att de händer. När det gäller att upptäcka bedrägerier upptäcker du nätverket av aktörer; när det gäller rekommendationer kartlägger du dolda affiniteter; inom IoT spårar du kedjor av fel. Den kraften ger djupare insikt, snabbare upptäckt, och mer strategiska åtgärder.
Proffstips:
Identifiera en domän där relationer är viktiga (kund-360, leveranskedja, bedrägeri eller IoT).
Pilotera en grafmodell med hjälp av en grafdatabas eller utöka din datasjö med ett lager av kunskapsgrafer.
Se till att ditt team skapar tydliga enhets- och relationsdefinitioner (noder och kanter) och inkluderar härkomst och styrning så att dina insikter förblir tillförlitliga.
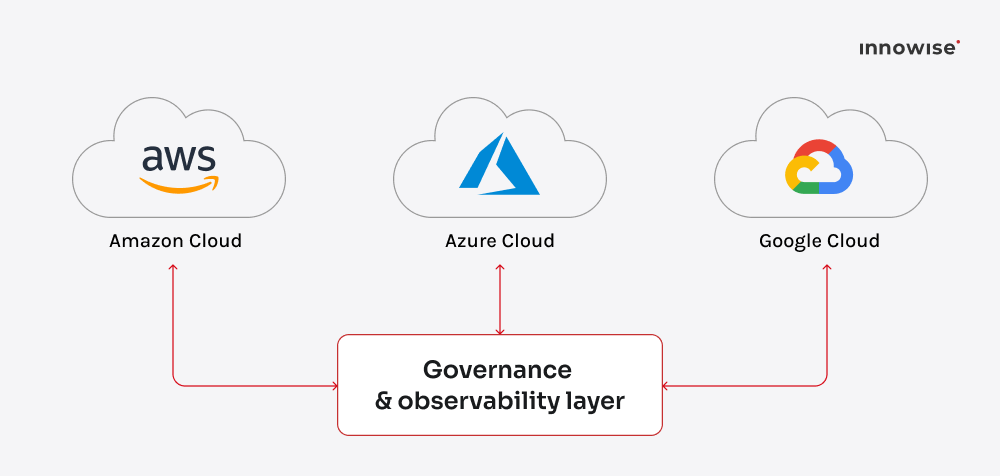
6. Multi-moln- och hybriddatastrategier
År 2026 ses det alltmer som en risk att förlita sig enbart på en enda molnleverantör, ungefär som att lägga alla sina investeringar i en enda aktie. Medan många organisationer fortfarande främst använder en plattform, spelar de mest strategiskt avancerade företagen nu multi-moln-spelet. De balanserar tjänster från AWS, Azure och Google Moln för att undvika inlåsning och få ut det bästa förhållandet mellan prestanda och kostnad från varje plattform.
Hybridlösningar ökar också. Det är när organisationer kombinerar molntjänster med sina befintliga lokala datacenter. Skälen till denna hybridstrategi går djupare än att bara behålla känsliga data lokalt:
Regional efterlevnad: Uppfylla specifika lagar om dataresidens (som GDPR) som föreskriver att vissa uppgifter måste stanna inom nationella gränser.
Äldre system: Fortsätta att använda högpresterande, icke-migrerbara äldre system eller stordatorer som är kritiska för kärnverksamheten.
Avkastning på kapitalinvesteringar: Maximera avkastningen på tidigare betydande investeringar i lokal hårdvara och infrastruktur.
Haken? Komplexitet. Att sprida arbetsbelastningar över moln innebär fler rörliga delar: olika API:er, faktureringssystem och styrningsregler. Vinnarna är de som automatiserar orkestrerings- och övervakningslagret. Tänk på frågemotorer för flera moln, enhetlig identitetshantering och observerbara verktyg som spårar latens och kostnader i realtid.
Proffstips:
Kartlägg dina arbetsbelastningar och ta reda på vad som verkligen drar nytta av multi-moln: analys, lagring eller beräkning.
Använd molnagnostiska arkitekturer som bygger på öppna format som Parquet, Delta eller Iceberg.
Anta FinOps-verktyg för att övervaka utgifter mellan olika leverantörer och undvika “räkningschock”.
Håll styrningen central: en åtkomstpolicy, en verifieringskedja, en bild av datahistoriken, oavsett var den finns.
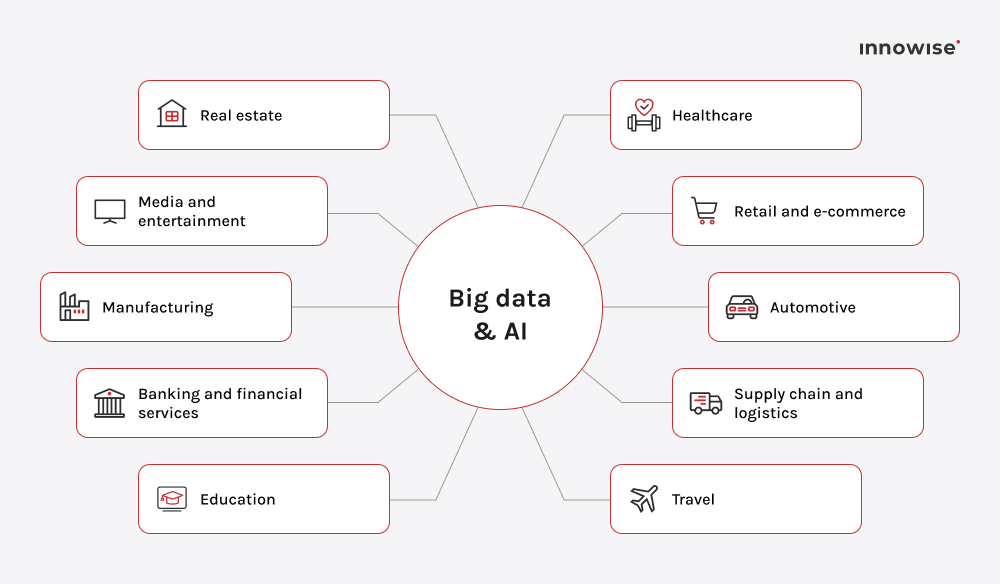
7. Branschspecifika lösningar för stora datamängder
Generiska dataplattformar är fantastiska. Tills de börjar lösa ingenting särskilt. Det är därför vi i 2026, företag i konkurrensutsatta, högrisk- eller reglerade branscher har fått nog av generiska verktyg. De vill ha branschanpassade lösningar som talar deras språk, hanterar deras regelverk och levererar resultat i stället för instrumentpaneler som ser imponerande ut men betyder lite.
Så varför efterfrågar företagen plötsligt dessa specialiserade lösningar i 2026? Det kokar verkligen ner till tre stora saker:
Regleringstryck: För att kunna följa lagar och regler utan anpassad kodning behöver företagen lösningar med ramverk för styrning som redan är inbyggda för deras specifika sektor.
AI-drivna domänmodeller: Eftersom AI bara är så bra som sin utbildning behöver organisationer lösningar som levereras med förutbildad domänexpertis och vokabulär för att säkerställa korrekta insikter.
Efterfrågan på färdigbyggd expertis: Ärligt talat är organisationer trötta på att slösa tid och pengar på att lära generiska verktyg hur deras bransch fungerar. De vill ha lösningar med färdigpaketerade kopplingar, dataordlistor och ramverk för efterlevnad som passar rakt in i deras dagliga arbetsflöden. Allt handlar om att få resultat och att eliminera det smärtsamma och kostsamma översättningssteget.
Det är därför marknaden skiftar mot domänspecifika dataprodukter: förbyggda modeller, kopplingar och ramverk för efterlevnad som passar direkt in i verkliga arbetsflöden. Denna specialisering uppvisar redan en massiv tillväxt på vertikala marknader. Till exempel, enligt Visiongain, är marknaden för analys av hälso- och sjukvården ensam kommer att uppgå till $101 miljarder senast 2031, som drivs av denna typ av specialisering.
Proffstips:
Sluta jaga analysplattformar som passar alla. Gör det istället, Välj verktyg som är byggda för din branschs dataproblemFrån EMR-standarder inom sjukvården till AML-regler inom banksektorn.
Pressa dina leverantörer på domänexpertis, inte bara deras tekniska stack.
Bygg små, resultatdrivna pilotprojekt kring dina största operativa smärtpunkter och skala upp det som faktiskt fungerar.
8. Edge computing för stora datamängder
År 2026, är kravet på omedelbara, automatiserade åtgärder av yttersta vikt. Även om molnet fortfarande är viktigt inser företagen att det kostar för mycket tid och pengar att skicka varje enskild byte av data till en avlägsen server för bearbetning.
Edge computing är lösningen. Det för databehandlingen närmare där den genereras: sensorer, maskiner, enheter och till och med bilar. I stället för att skicka terabyte över nätverket bearbetar du det viktiga lokalt och agerar direkt.
Varför exploderar denna trend nu?
IoT-explosion: Miljarder sensorer innebär att centraliserad bearbetning helt enkelt är för dyrt och långsamt.
AI vid kanten: Med lättviktsmodeller kan AI fatta beslut i realtid direkt på enheten, utan fördröjning i molnet.
Mandat i realtid: När det gäller områden med höga insatser (som att upptäcka fel på utrustningen) är millisekunder viktiga.
Detta har störst betydelse för branscher där snabbhet är livsviktigt: smarta fabriker som justerar produktionslinjer i farten, sjukhus som övervakar patienter i realtid eller detaljhandelskedjor som hanterar prissättningen dynamiskt baserat på lokal efterfrågan. Och det finns pengar för att backa upp det: IDC:s prognoser globala utgifterna för edge computing-lösningar kommer att växa med ~13,8% CAGR och nå nästan $380 miljarder till 2028.
De smartaste organisationerna ersätter inte molnet, de kompletterar det. De använder en hybridkonfiguration: lokal bearbetning för hastighet, molnlagring för skala. Resultatet är vackert: lägre latens, minskade bandbreddskostnader och snabbare beslut som faktiskt gör skillnad.
Proffstips:
Börja med ett område där fördröjning gör ont. Kanske kvalitetskontroll i produktionen eller förebyggande underhåll inom logistiken.
Implementera edge analytics där och anslut det till ditt centrala molnsystem.
Definiera tydliga regler för vad som ska behandlas lokalt respektive centralt, och se till att styrningen är konsekvent i båda fallen.
9. Syntetiska data och integritetshöjande teknik
År 2026, Att få tillgång till verkliga data är svårare än någonsin: sekretesslagarna är strängare, tillsynsmyndigheterna är vaksamma och användarna är mycket mindre förlåtande. Det är därför vi behöver syntetiska data.
Trenden är explosionsartad nu eftersom GenAI bom har äntligen gjort syntetiska data tillräckligt högkvalitativa för att på ett tillförlitligt sätt efterlikna komplex, verklig information. Företag förlitar sig alltmer på dessa artificiella, statistiskt korrekta data för att träna massiva AI-modeller snabbare och billigare än med traditionella metoder, samtidigt som de automatiskt uppfyller tuffa efterlevnadsbehov som GDPR och EU:s AI-lag.
Verktyg för syntetisk data finns överallt: från finansföretag som tränar modeller för att upptäcka bedrägerier till vårdföretag som kör AI-diagnostik utan att exponera patientdata. Gartner förväntar sig det senast 2030, syntetiska data kommer att överträffa verkliga data i AI-utbildning, eftersom det är säkrare, snabbare och lättare att skala upp.
Proffstips:
Använd syntetiska data inom områden där efterlevnaden blockerar tillgången till verklig information (hälso- och sjukvård, finans eller HR-analys).
Integrera PET (Privacy-Enhancing Technologies) i din pipeline tidigt, inte som en eftertanke.
Genomför pilotprojekt där modellens prestanda jämförs med syntetiska och verkliga data, och följ upp hur det påverkar noggrannhet och partiskhet.
Ta kontroll över dina data - minska kostnaderna, öka effektiviteten
År 2026, analytics känns äntligen mänskligt. AI copilots och narrativa visualiseringsverktyg förvandlar nu data till tydliga berättelser istället för ändlösa diagram. Verktyg som Power BI Copilot, Tableau GPT, camelAI, och Lookers GenAI-lager kan ställa frågor, sammanfatta och förklara insikter på ett enkelt språk.
Tänk på dem som dina dataanalytiker. Du kan fråga “Hur utvecklades intäkterna det här kvartalet?” eller “Vilken kampanj gav den högsta avkastningen?” och få omedelbara svar i klarspråk. Verktyg som Power BI Copilot, Tableau GPT, och camelAI redan gör detta genom att koppla stora språkmodeller direkt till ditt företags data.
Proffstips:
Integrera copiloter i din analysstack, koppla dem till verifierade dataset och omforma instrumentpaneler utifrån berättelser, inte mätvärden.
Utbilda team i att validera AI-utdata och fokusera på “varför” bakom varje siffra.
11. Moln datalagring och uppkomsten av lakehouse
År 2026, har gränsen mellan datasjöar och datalager suddats ut. Den nya standarden är lakehouse architecture, som är en hybridmodell som kombinerar skalbarheten hos datasjöar med strukturen och prestandan hos lager. Du kan lagra ostrukturerad data, göra sökningar med SQL och köra maskininlärning. Allt på ett och samma ställe. Utan att behöva jonglera med tio olika plattformar.
Leverantörer som Databricks, Snowflake, och Google BigQuery är de som leder utvecklingen här.
Proffstips:
Om din infrastruktur fortfarande delar upp data mellan sjöar och lager, börja konsolidera.
Anta en Lakehouse-lösning som passar din stack och utbilda ditt team i att göra sökningar i både strukturerade och ostrukturerade dataset.
Prioritera öppna format som Parkett och Delta Lake för att undvika inlåsning av leverantörer.
Och när du väl är igång kan du börja lägga avancerad analys och maskininlärning direkt ovanpå. Det är där den verkliga ROI:n finns.
12. Dataobserverbarhet och DataOps
År 2026, Att hantera datapipelines utan observerbarhet är som att flyga ett plan med instrumentpanelen avstängd. Du kanske rör dig snabbt, men du har ingen aning om vad som går sönder. Dataobservabilitet är hur team får insyn i hälsan, färskheten och tillförlitligheten hos sina data. Det berättar för dig när något är fel, varför det hände och hur du fixar det innan instrumentpaneler börjar visa nonsens.
Så varför är detta viktigt nu? För att det inte går att ha styrning eller efterlevnad utan det.
Du måste styra: Observability-verktyg spårar hela dataresan (eller lineage) och ger dig de bevis du behöver för att upprätthålla kvalitetsstandarder och policyer i hela företaget.
Du måste rätta dig efter detta: Eftersom verktygen loggar allt (vem som rörde uppgifterna, hur de omvandlades) genererar de den exakta verifieringskedja som krävs för att uppfylla kraven från tillsynsmyndigheter (t.ex. GDPR).
Detta går hand i hand med DataOps, vilket automatiserar saker som testning och driftsättning. Tillsammans ger observability och DataOps dig en tillförlitlig, kompatibel och bergfast datastomme med färre överraskningar och snabbare återhämtningstider.
Proffstips:
Börja med att instrumentera dina viktigaste datapipelines med observationsverktyg som spårar färskhet, ursprung och anomalier.
Behandla datapipelines som produktionssystem och övervaka dem kontinuerligt, inte bara när något går sönder.
Koppla ihop observerbarhet med DataOps-metoder: automatisera testning, implementera versionshantering för omvandlingar och skapa tydligt ägande av varje dataset.
13. FinOps för data och AI
Har molnräkningar någonsin hållit dig vaken om natten? När datavolymer exploderar och AI-arbetsbelastningar multipliceras, FinOps (finansiell verksamhet för moln och data) blir avgörande. Målet är enkelt: förstå vart varje dollar i dataekosystemet tar vägen och se till att den faktiskt används för att köpa affärsvärde, inte bara större servrar.
Att träna stora modeller, lagra petabytes med data och köra oändliga frågor kan snabbt tära på budgeten. FinOps-team använder nu analys och automatisering för att följa upp kostnader i realtid, upptäcka ineffektivitet och prognostisera användningen mellan avdelningar. Moln-leverantörer erbjuder till och med inbyggda verktyg för detta (AWS Cost Explorer, Google Moln Billing, Azure Cost Management), men de verkliga vinsterna kommer från att integrera finansiella mätvärden direkt i dina dataarbetsflöden.
Proffstips:
Ta in FinOps i din datastrategi tidigt.
Tagga varje dataset, pipeline och modell efter kostnadsställe och affärsinnehavare.
Spåra utgifter för lagring, databehandling och AI-utbildning med instrumentpaneler i realtid.
Uppmuntra dina datateam att övervaka resursanvändningen lika noga som de övervakar prestandamätvärdena.
Och när du är osäker, automatisera. Använd AI-drivna rekommendationer för att stänga av inaktiva kluster eller ombalansera arbetsbelastningar.
14. Förklarligt och ansvarsfullt AI
År 2026, AI styr en så stor del av verksamheten att det inte längre går att “lita på modellen”. Styrelser, tillsynsmyndigheter och kunder förväntar sig alla öppenhet. De vill veta Varför en algoritm fattade ett beslut, inte bara resultatet. Det är därför Förklarlig AI (XAI) och Ansvarig AI blir allt vanligare. Tillsammans gör de maskininlärning mindre av en svart låda och mer av ett system som du kan styra.
Bankerna använder redan förklaringsmodeller att motivera kreditbeslut för revisorer. Vårdgivare förlitar sig på dem för att visa hur diagnostiska algoritmer kommer fram till slutsatser. Även HR-system granskas för att bevisa att anställningsrekommendationer är rättvisa. När beslut påverkar människor eller vinster är blind tilltro till AI inte strategi; det är en risk.
Proffstips:
Upprätta interna policyer för förklarbarhet i alla AI-projekt.
Kräv att varje modell har en tydlig motivering för sina förutsägelser och ett register över dess träningsdata.
Använd förklaringsverktyg som SHAP, LIME, eller din molnleverantörs inbyggda XAI-funktioner.
Och gör ansvar till en del av ditt arbetsflöde: inkludera juridiska frågor, efterlevnad och HR i din AI-styrgrupp.
15. Multimodal analys
Fram till 2026, utveckling av big data kommer att gå bortom tabeller och instrumentpaneler och in i en ny era av multimodal analys. Här kombineras text-, bild-, video- och sensordata för att skapa en komplett, kontextrik bild. I stället för att analysera kundfeedback och försäljningssiffror separat kan teamen nu korrelera samtalsutskrifter, produktfoton och användarbeteende i en enda arbetsyta.
Låter som sci-fi, eller hur? Men plattformar som Databricks MosaicML, Anthropic's Claude för data, och OpenAI: s GPT-4 Turbo med vision redan hanterar data i flera format. Resultatet är häftigt. Sammanhangsrika insikter känns nästan intuitiva. Föreställ dig att du kan förutse fel på utrustningen genom att korsanalysera vibrationsloggar, värmebilder och underhållsanteckningar. Det är vad multimodal analys möjliggör.
Proffstips:
Granska var dina data finns och hur fragmenterade de är i olika format.
Om dina analyser bara fokuserar på strukturerad data kan du börja lägga till ostrukturerade källor: kundsamtal, bilder och videoflöden.
Investera i en plattform som stöder multimodal inmatning, helst en som är byggd med vektordatabaser och semantisk sökning.
Och viktigast av allt: uppmuntra teamen att tänka längre än till siffrorna.
Förenkla dina dataarbetsflöden och öppna upp för nya möjligheter
Och den sista på listan över viktiga trender inom big data är Beslutsintelligens (DI). Den blandar datavetenskap, DI-system kombinerar psykologi och affärslogik för att hjälpa organisationer att fatta smartare beslut snabbare. I stället för att kasta hundra mätvärden på dig modellerar DI-system hur val leder till resultat och simulerar sedan scenarier innan du bestämmer dig.
Tänk på det som en analys som ger svar på “Vad händer om vi faktiskt gör det här?”, inte bara “Vad hände förra kvartalet?” Detaljhandlare använder det för att testa prisstrategier före lansering. Banker använder det för att simulera riskexponering i olika portföljer. Till och med HR-avdelningar använder DI för att förutse effekterna av att anställa och behålla personal innan policyer införs.
Marknaden visar på detta skifte: den globala marknaden för beslutsunderlag uppskattades till $15,22 miljarder år 2024 och väntas uppgå till $36,34 miljarder år 2030, och växer med en CAGR på cirka 15,4%.
Proffstips:
Börja med att kartlägga hur besluten fattas: vem som fattar dem, vilka data de använder och hur framgång mäts.
Identifiera sedan områden som upprepas ofta eller där mycket står på spel och där simulering kan förhindra misstag.
Använd ett DI-verktyg som kopplar samman affärslogik med aktuella data och definiera KPI:er för beslutsresultat, inte bara datanoggrannhet.
Avslutning
Så hur ser framtiden ut för big data? 2026 ger en ny nivå av mognad. Fokus ligger nu på att välja de verktyg och metoder som faktiskt skapar effekt. Företag som kopplar samman teknik med tydliga mål kommer att se snabbare tillväxt och starkare resultat.
Använd AI där det sparar tid och förbättrar noggrannheten. Bygg ett datanät som hjälper teamen att arbeta tillsammans i stället för i silos. Investera i realtidsanalys som hjälper dig att agera i rätt ögonblick, inte i efterhand.
Årets ledare förstår en sak: värde kommer från att tillämpa data på ett ändamålsenligt sätt. Välj det som passar din strategi, se till att det fungerar i alla team och låt data bli motorn som driver varje smart åtgärd du gör.
Philip ger skarpt fokus på allt som har med data och AI att göra. Han är den som ställer rätt frågor tidigt, skapar en stark teknisk vision och ser till att vi inte bara bygger smarta system - vi bygger rätt system, för verkligt affärsvärde.
En djupdykning i rollen som Frontier Deployment Engineer och hur FDE:er omvandlar experimentella AI-piloter till säkra, mätbara och skalbara AI-produktionssystem.
Upptäck de bästa trenderna inom mjukvaruutveckling för 2026. Utforska de senaste teknikerna och insikterna som kommer att förändra programvaruindustrin!
Upptäck de bästa trenderna inom mjukvaruutveckling för 2026. Utforska de senaste teknikerna och insikterna som kommer att förändra programvaruindustrin!

 Anlita oss
Anlita oss