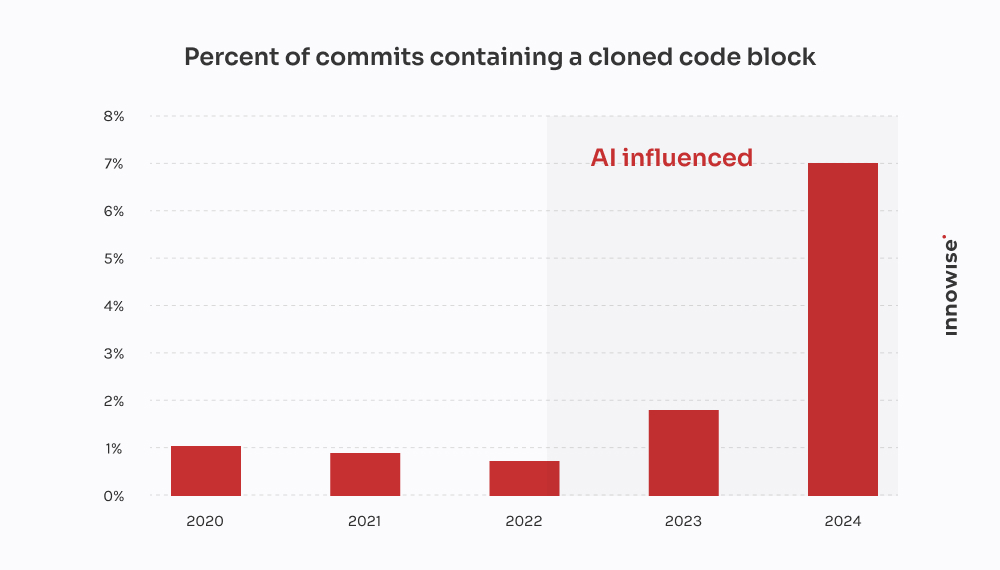
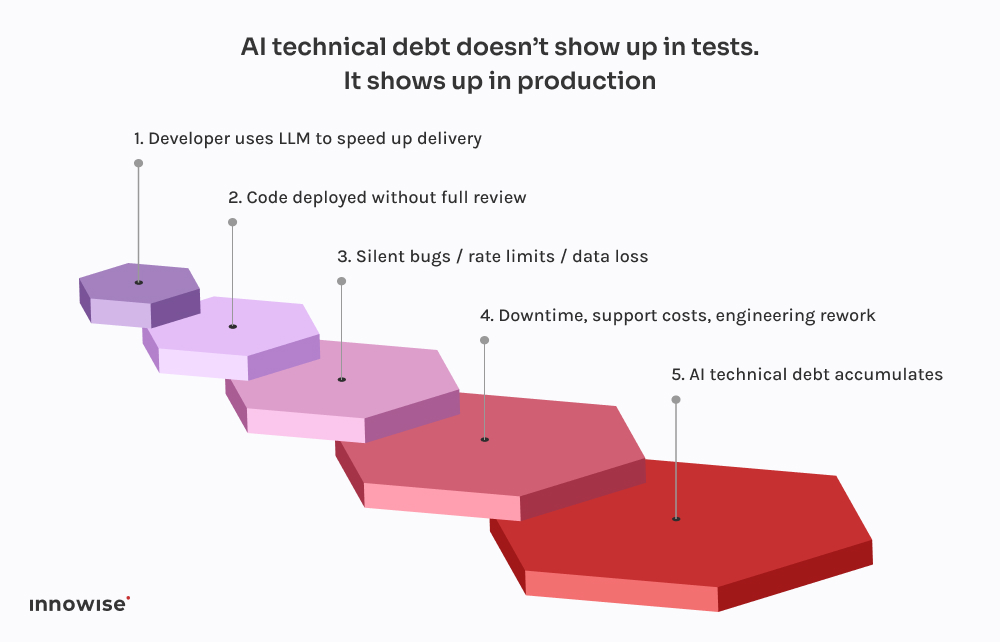
Questa proviene da un'azienda fintech in rapida crescita.
Stavano lanciando una nuova versione del loro modello di dati dei clienti, dividendo un grande campo JSONB in Postgres in più tabelle normalizzate. Roba abbastanza standard. Ma con scadenze strette e poche mani, uno degli sviluppatori ha deciso di "accelerare le cose" chiedendo a ChatGPT di generare uno script di migrazione.
All'apparenza sembrava tutto a posto. Lo script analizzava il JSON, estraeva le informazioni sul contatto e le inseriva in un nuovo file user_contacts tavolo.
Così l'hanno eseguito.
Nessuna prova a secco. Nessun backup. Si è passati direttamente allo staging che, come si è scoperto, condivideva i dati con la produzione attraverso una replica.
Qualche ora dopo, l'assistenza clienti ha iniziato a ricevere e-mail. Gli utenti non ricevevano le notifiche di pagamento. Altri avevano numeri di telefono mancanti nei loro profili. A quel punto ci hanno chiamato.
Cosa è andato storto
Il problema è riconducibile allo script. Eseguiva l'estrazione di base, ma faceva tre assunzioni fatali:
- Non ha gestito
NULL o chiavi mancanti all'interno della struttura JSON. - Ha inserito record parziali senza convalida.
- Ha utilizzato
ON CONFLICT DO NOTHING, per cui ogni inserimento fallito viene ignorato silenziosamente.
Risultato: circa 18% dei dati di contatto è stato perso o danneggiato. Nessun registro. Nessun messaggio di errore. Solo una tranquilla perdita di dati.
Cosa è stato necessario per risolvere il problema
Abbiamo assegnato a un piccolo team il compito di sbrogliare la matassa. Ecco cosa abbiamo fatto:
- Diagnosi e repliche (4 ore) Abbiamo ricreato lo script in un ambiente sandbox e lo abbiamo eseguito su un'istantanea del database. In questo modo abbiamo confermato il problema e mappato esattamente ciò che mancava.
- Audit forense dei dati (8 ore) Abbiamo confrontato lo stato di rottura con i backup, identificato tutti i record con dati mancanti o parziali e li abbiamo confrontati con i registri degli eventi per rintracciare gli inserimenti falliti e il motivo.
- Riscrittura della logica di migrazione (12 ore) Abbiamo riscritto l'intero script in Python, aggiunto una logica di validazione completa, creato un meccanismo di rollback e integrato nella pipeline CI del cliente. Questa volta sono stati inclusi i test e il supporto per le prove a secco.
- Recupero manuale dei dati (6 ore) Alcuni record non erano recuperabili dai backup. Abbiamo recuperato i campi mancanti da sistemi esterni (le API del loro CRM e del provider di e-mail) e ripristinato manualmente il resto.
Tempo totale: 30 ore di ingegneria
Due ingegneri, tre giorni. Costo per il cliente: circa $4,500 in tasse di servizio.
Ma il colpo maggiore è stato dato dalle ricadute sui clienti. Le notifiche non andate a buon fine hanno portato a mancati pagamenti e alla rinuncia all'acquisto. Il cliente ci ha detto di aver speso almeno $10,000 per i ticket di assistenza, le compensazioni SLA e i crediti di avviamento per quell'unico script mal riuscito.
La cosa ironica è che uno sviluppatore senior avrebbe potuto scrivere la migrazione corretta in quattro ore. Ma la promessa di velocità di AI ha finito per costare loro due settimane di pulizia e danni alla reputazione.
 Assumeteci
Assumeteci