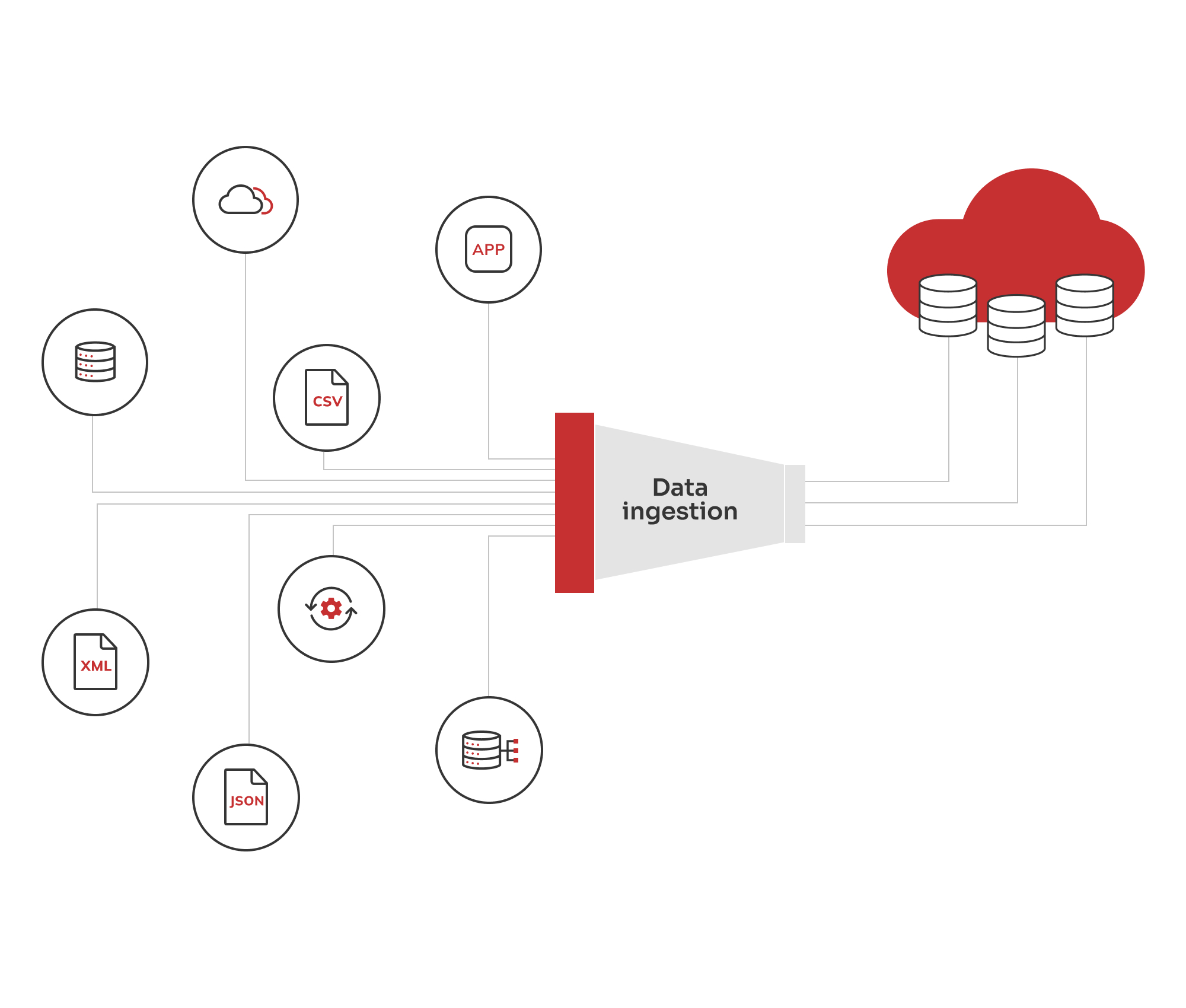
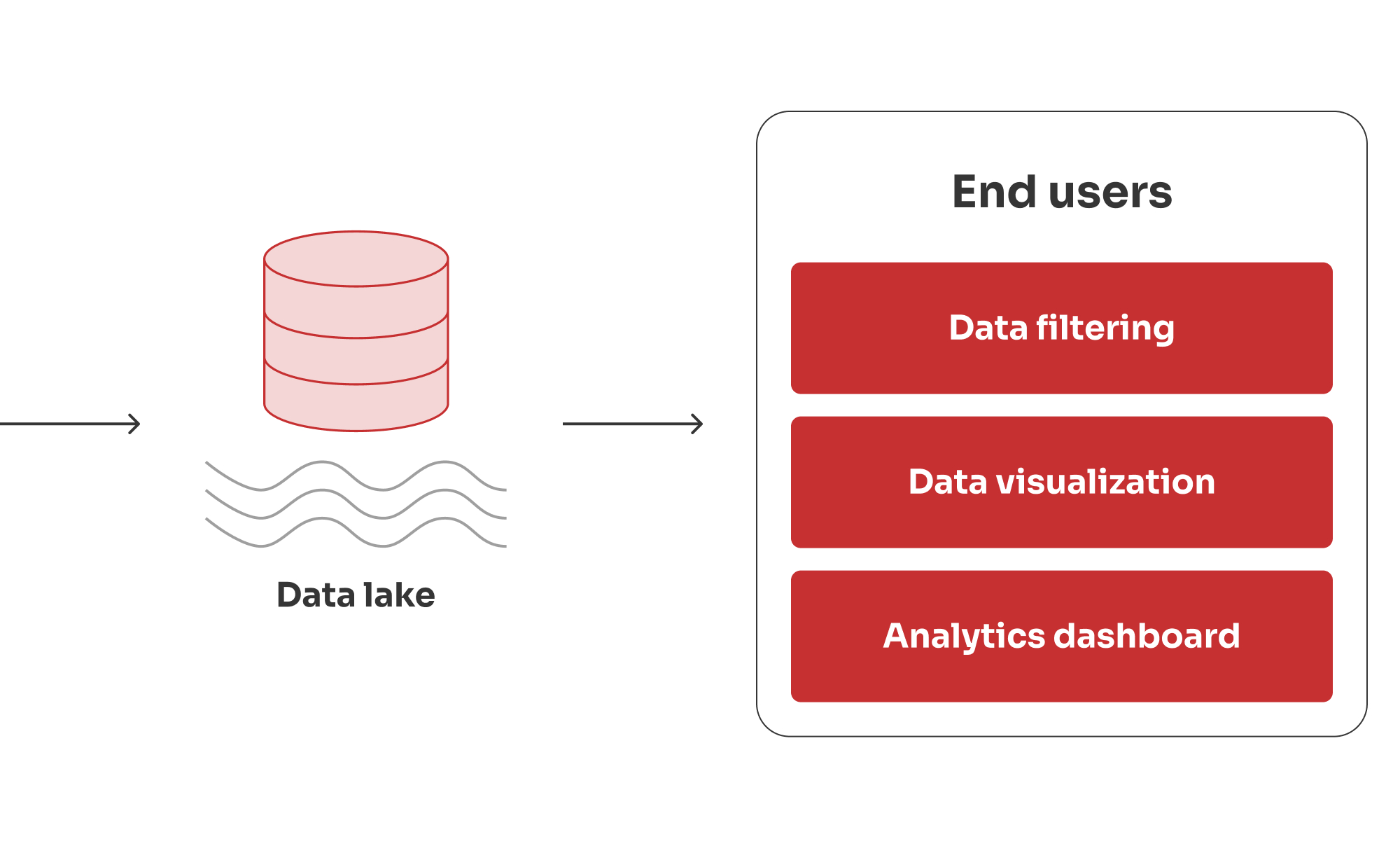
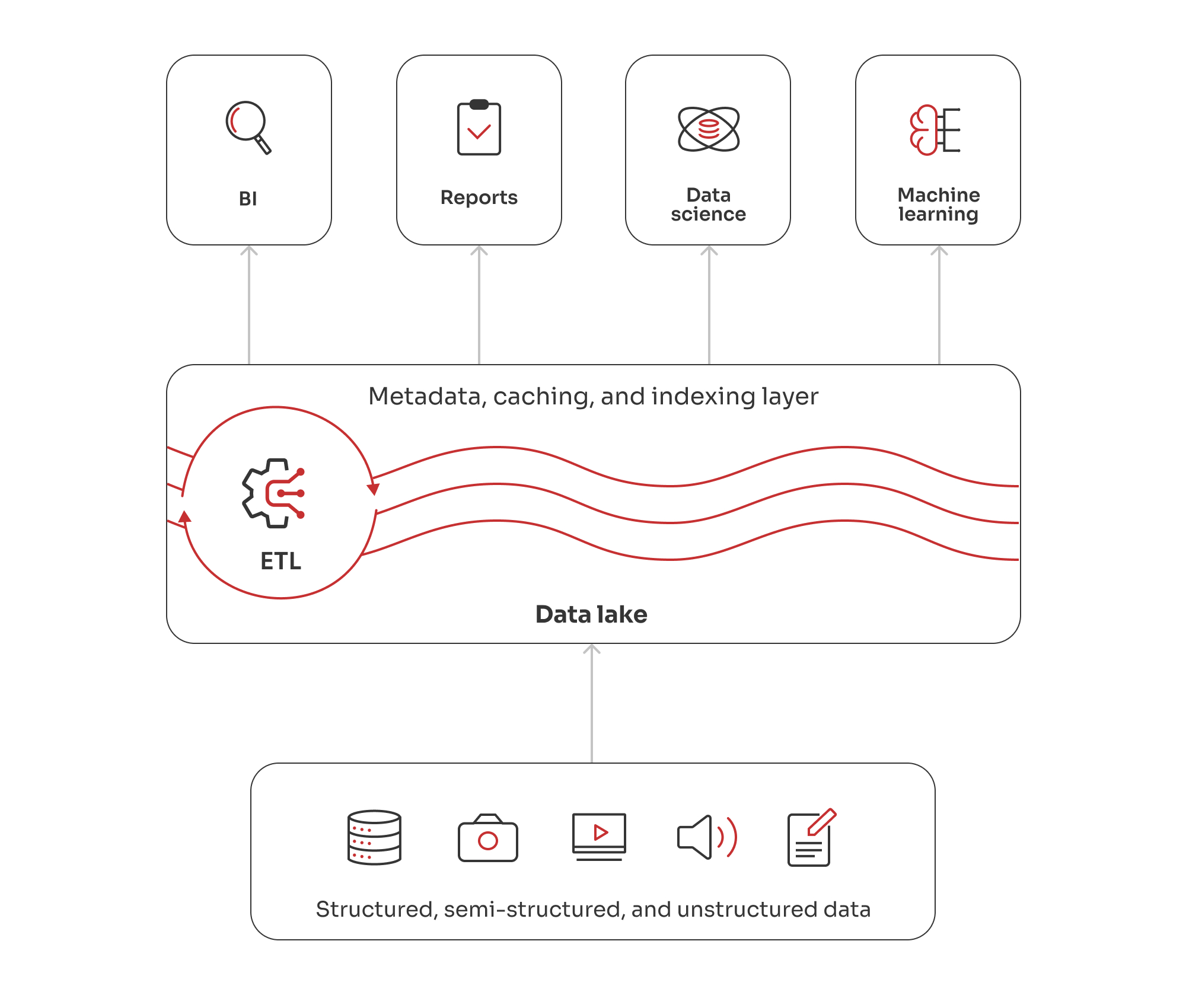
Die Goldschicht ist die Spitze unserer Data-Lake-Architektur. Hier werden die Daten in analysefähige Informationen umgewandelt, die speziell für Analysen, Berichte und Entscheidungsfindung auf höchster Ebene zugeschnitten sind. Die Daten aus der Silberschicht werden weiter aggregiert, um umfassende Zusammenfassungen auf hoher Ebene zu erstellen. Wir haben uns darauf konzentriert, die Daten so zusammenzufassen, dass sie mit den wichtigsten Geschäftsmetriken und -zielen übereinstimmen, z. B. mit Kreditrisikobewertungen, Markttrends oder Kundensegmentierung.
Unsere Entwickler entwarfen und implementierten interaktive Dashboards und Berichte, die den Entscheidungsträgern der Bank Einblicke und Visualisierungen in Echtzeit bieten. Mit dem Schwerpunkt auf Sicherheit haben wir einen robusten Data-Governance-Rahmen geschaffen, um die Qualität, Nutzbarkeit und Sicherheit der Daten zu verwalten. Unsere Ingenieure sorgten für eine skalierbare Architektur, die wachsende Datenmengen und -komplexität ohne Leistungseinbußen bewältigt und die Integrität und Zuverlässigkeit der Analyseergebnisse gewährleistet.
In der Goldschicht haben wir Daten in ein strategisches Gut verwandelt, das es der Bank ermöglicht, fundierte Entscheidungen zu treffen, die Kundenbedürfnisse besser zu verstehen und in der wettbewerbsintensiven Bankenbranche die Nase vorn zu haben.
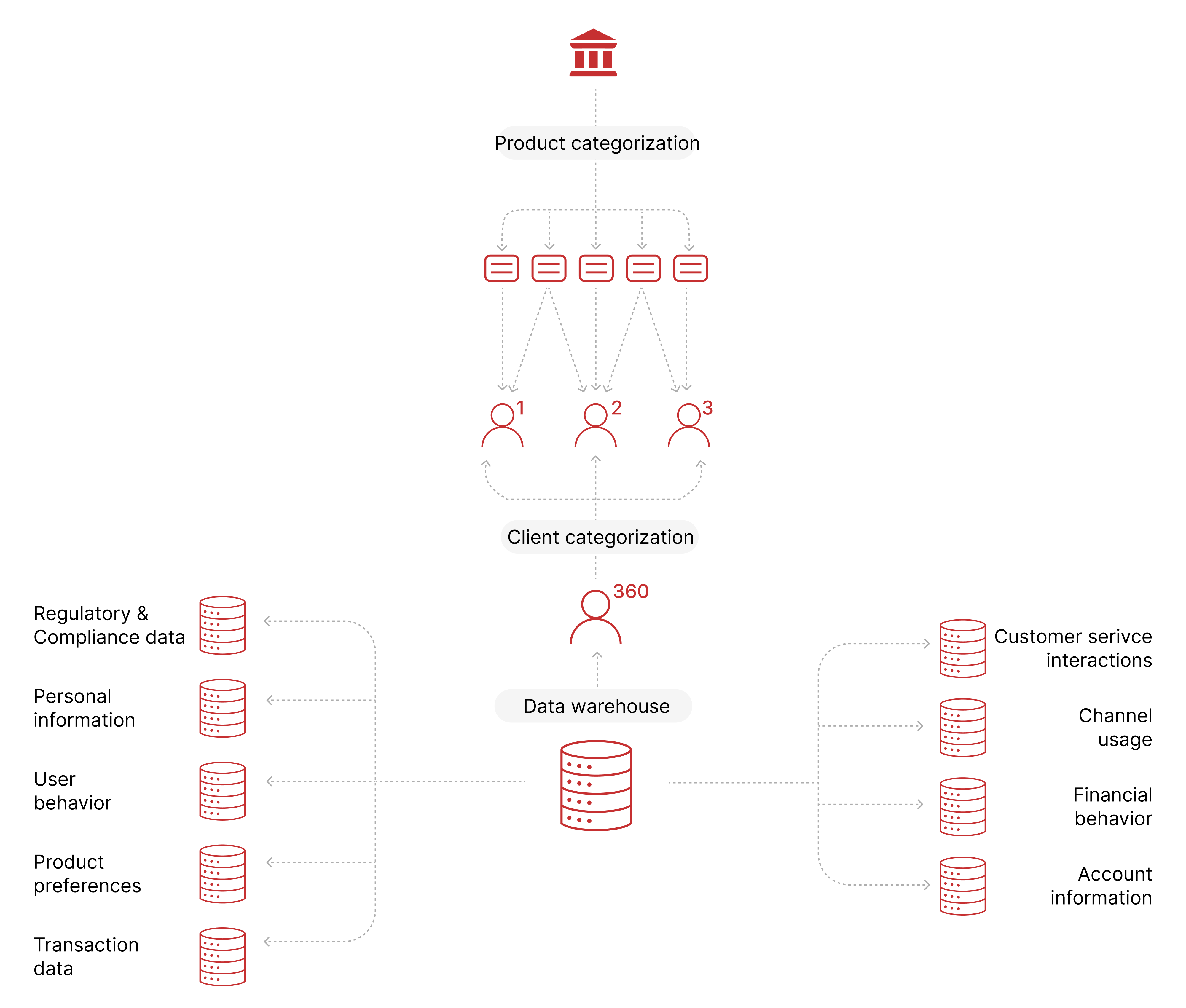
Auf der Grundlage verfeinerter bankbezogener Daten ermöglichte Innowise dem Kunden, die Methoden Next Best Action (NBA) und Next Best Offer (NBO) zu implementieren. NBA priorisiert einen kundenzentrierten Ansatz und analysiert die letzten Interaktionen, um die am besten geeigneten Maßnahmen vorzuschlagen, wie z. B. das Versenden von Geburtstagsnachrichten, die Verbesserung der Servicequalität, das Einholen von Feedback, die Bereitstellung von Onboarding-Anweisungen und vieles mehr. Durch den Einsatz von Predictive Analytics wählt NBA Maßnahmen aus, die auf die aktuelle Situation des Kunden zugeschnitten sind und auf positive Ergebnisse abzielen. Im Gegenzug optimiert NBO die Auswahl von personalisierten Angeboten aus der umfangreichen Produktpalette eines Kunden. NBO bewertet und schlägt automatisch Produkte vor, die bei den Kunden auf Resonanz stoßen, indem es Angebote zur richtigen Zeit, zum richtigen Preis und über die effektivsten Kanäle bereitstellt.
Darüber hinaus konsolidierten unsere Entwickler Daten aus verschiedenen Tabellen und Modellen, die im Data Warehouse gespeichert waren, um umfassende, kohärente und praktische Profile für jeden Kunden zu erstellen, die fundiertere Entscheidungen und Maßnahmen ermöglichen. Der umfassende und durchdachte Ansatz zur Verwaltung analysebereiter Daten stellt sicher, dass die Bank ihr Datenpotenzial voll ausschöpfen, die Konversionsraten erhöhen und das Wachstum vorantreiben kann.

 Entwickler finden
Entwickler finden