 Contrate-nos
Contrate-nos
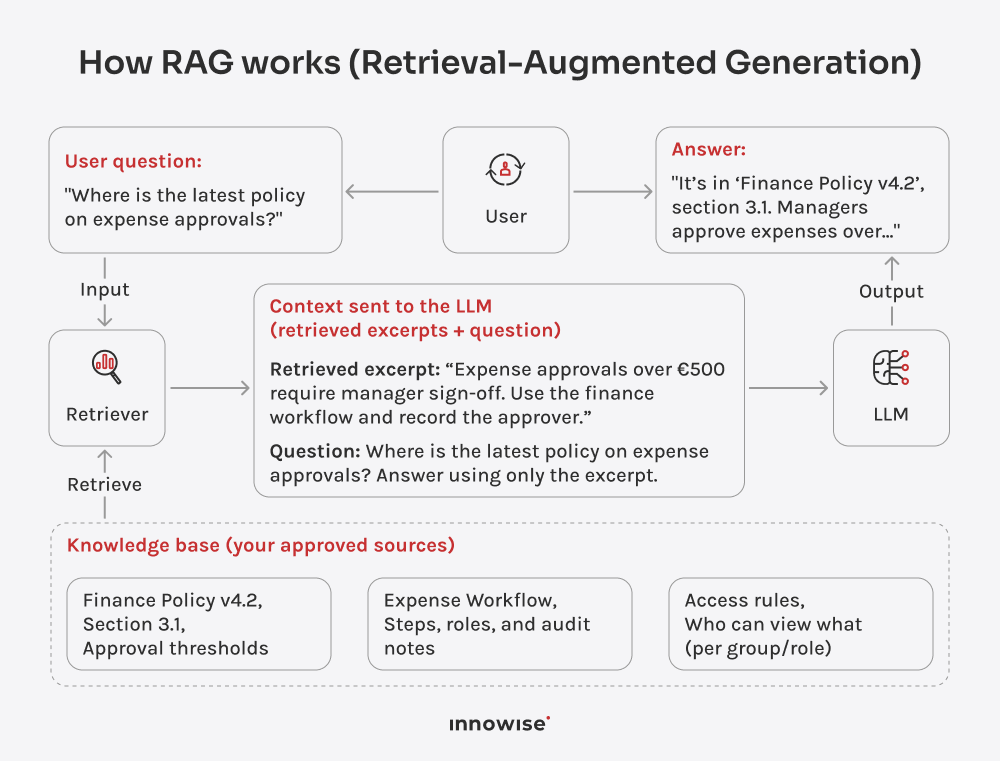
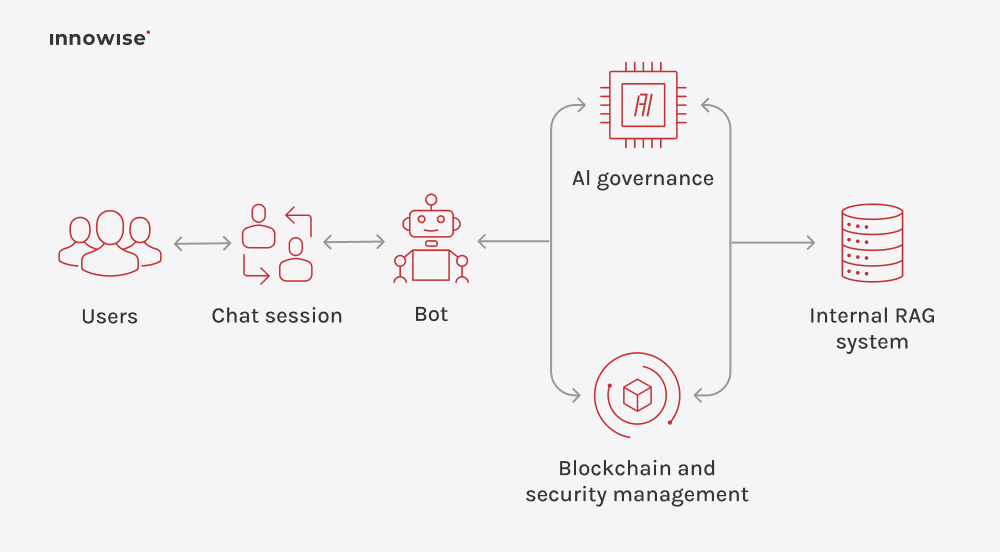
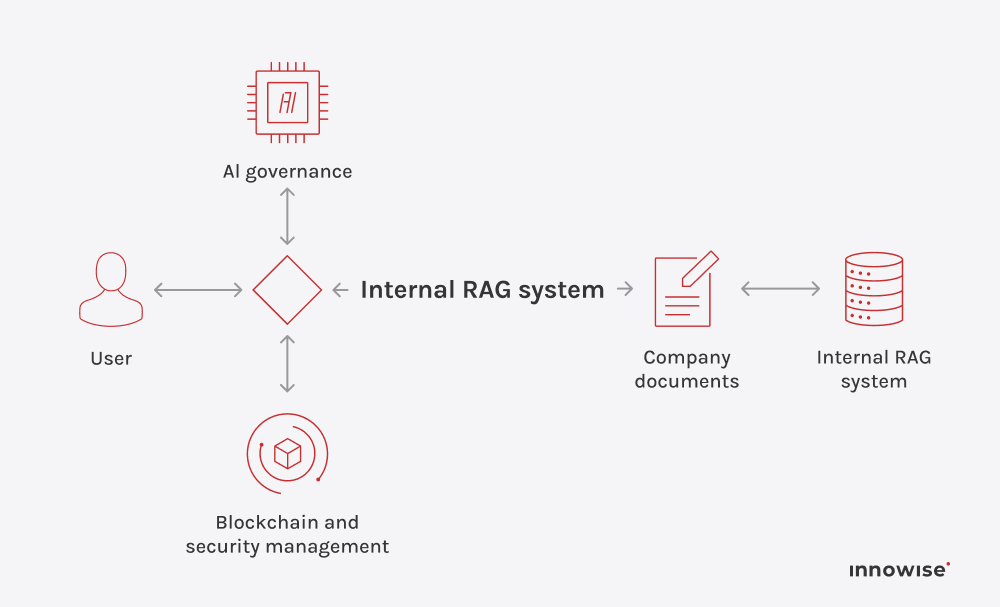
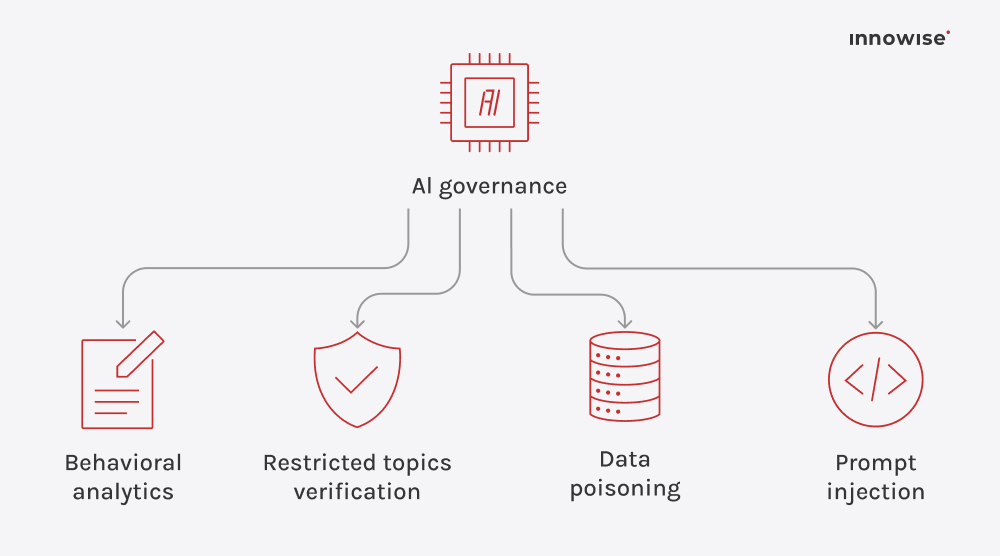


Pode utilizar documentos internos, artigos da base de conhecimentos, páginas wiki, conteúdos de suporte e outras fontes de texto que aprove. A chave é que o utilizador controla as fontes e as regras de acesso.












Obrigado!
A sua mensagem foi enviada.
Processaremos o seu pedido e contactá-lo-emos logo que possível.
