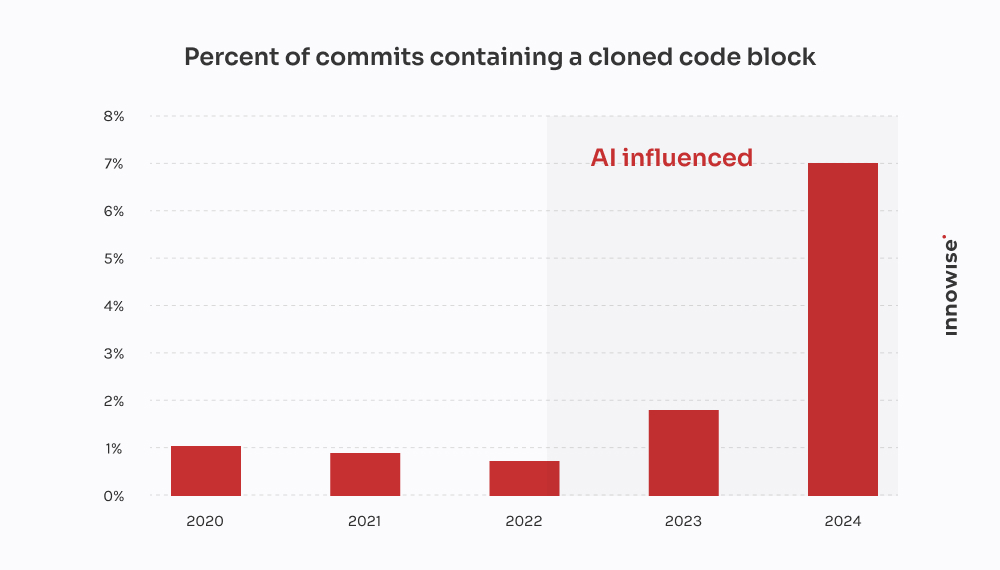
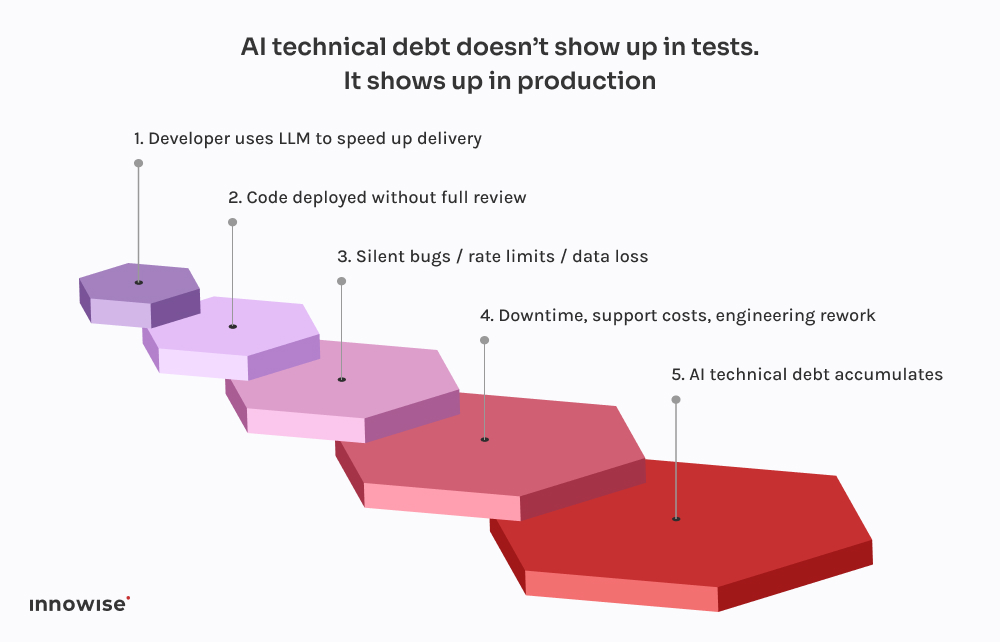
This one came from a fast-growing fintech company.
They were rolling out a new version of their customer data model, splitting one large JSONB field in Postgres into multiple normalized tables. Pretty standard stuff. But with tight deadlines and not enough hands, one of the developers decided to “speed things up” by asking ChatGPT to generate a migration script.
It looked good on the surface. The script parsed the JSON, extracted contact info, and inserted it into a new user_contacts table.
So they ran it.
No dry run. No backup. Straight into staging, which, as it turns out, was sharing data with production through a replica.
A few hours later, customer support started getting emails. Users weren’t receiving payment notifications. Others had missing phone numbers in their profiles. That’s when they called us.
What went wrong
We traced the issue to the script. It did the basic extraction, but it made three fatal assumptions:
- It didn’t handle
NULL values or missing keys inside the JSON structure. - It inserted partial records without validation.
- It used
ON CONFLICT DO NOTHING, so any failed inserts were silently ignored.
Result: about 18% of the contact data was either lost or corrupted. No logs. No error messages. Just quiet data loss.
What it took to fix
We assigned a small team to untangle the mess. Here’s what we did:
- Diagnosis and replication (4 hours) We recreated the script in a sandbox environment and ran it against a snapshot of the database. That’s how we confirmed the issue and mapped exactly what went missing.
- Forensic data audit (8 hours) We compared the broken state with backups, identified all records with missing or partial data, and matched them against event logs to trace which inserts failed and why.
- Rewriting the migration logic (12 hours) We rewrote the entire script in Python, added full validation logic, built a rollback mechanism, and integrated it into the client’s CI pipeline. This time, it included tests and dry-run support.
- Manual data recovery (6 hours) Some records were unrecoverable from backups. We pulled missing fields from external systems (their CRM and email provider APIs) and manually restored the rest.
Total time: 30 engineering hours
Two engineers, three days. Cost to client: around $4,500 in service fees.
But the bigger hit came from customer fallout. Failed notifications led to missed payments and churn. The client told us they spent at least $10,000 on support tickets, SLA compensation, and goodwill credits over that one botched script.
The ironic thing is that a senior developer could’ve written the correct migration in maybe four hours. But the promise of AI speed ended up costing them two weeks of cleanup and reputation damage.

 Hire
Hire