 Hire us
Hire us


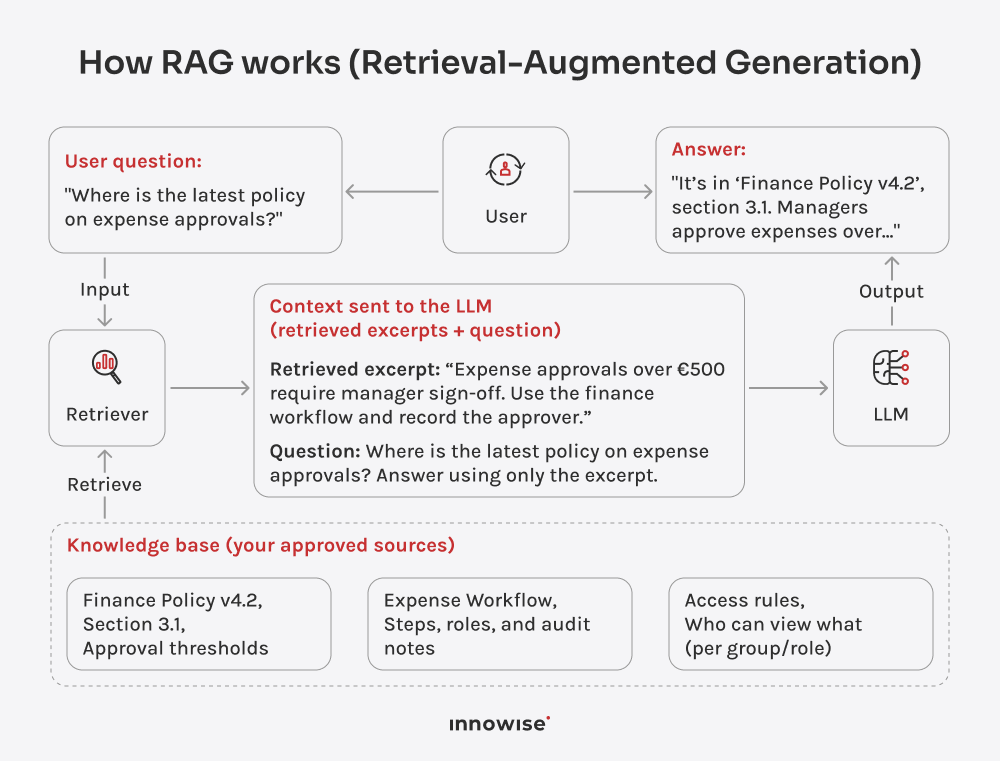
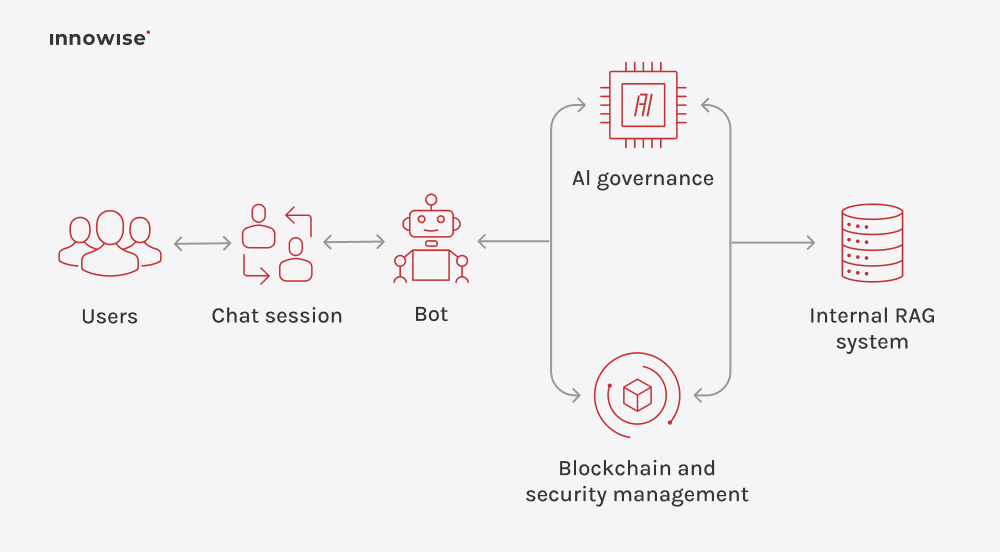
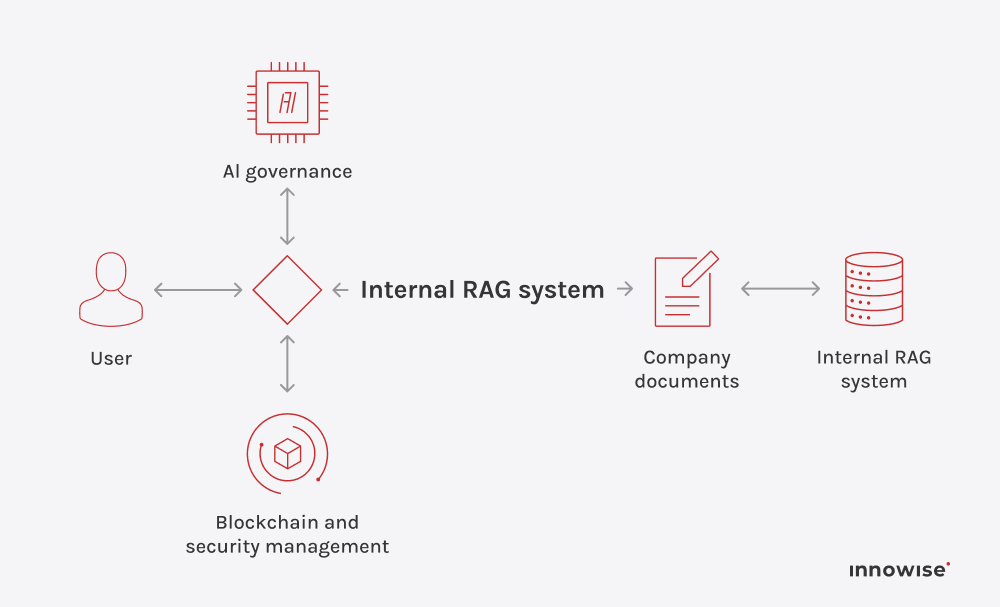
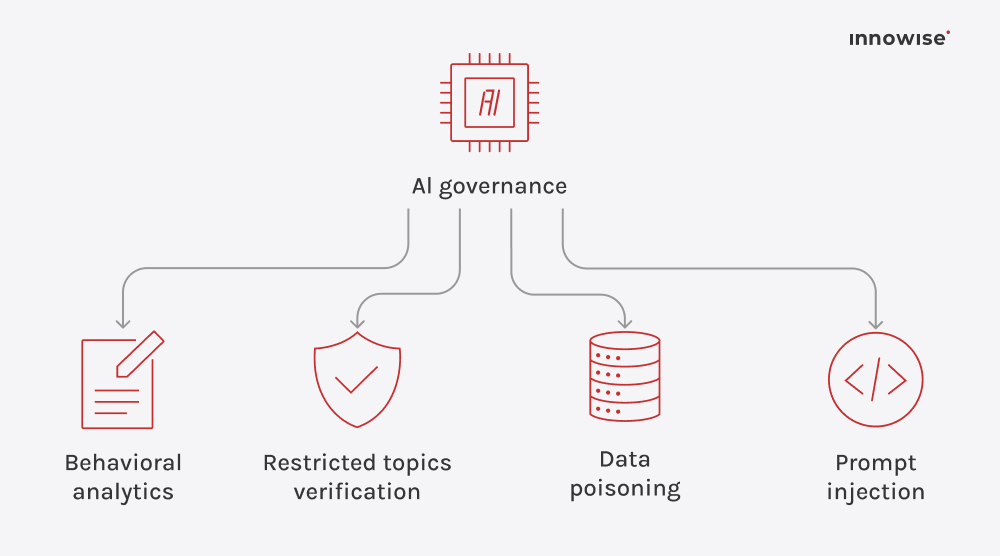


It can use internal documents, knowledge base articles, wiki pages, support content, and other text sources you approve. The key is that you control the sources and the access rules.












Thank you!
Your message has been sent.
We’ll process your request and contact you back as soon as possible.

