Esta veio de uma empresa de fintech em rápido crescimento.
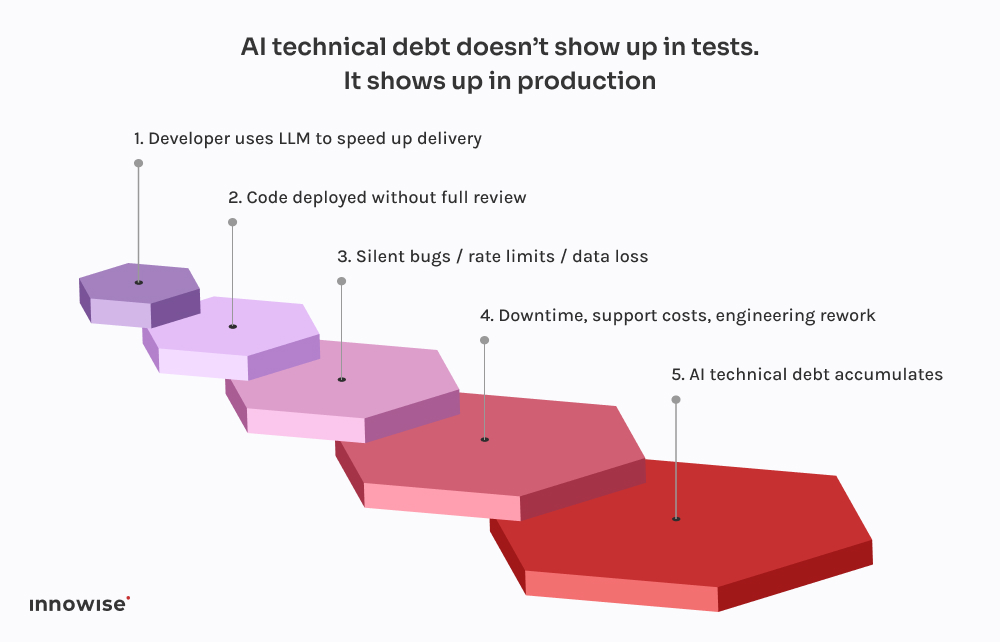
Eles estavam a lançar uma nova versão do seu modelo de dados de clientes, dividindo um grande campo JSONB no Postgres em várias tabelas normalizadas. Coisas bastante comuns. Mas com prazos apertados e sem mãos suficientes, um dos programadores decidiu "acelerar as coisas" pedindo ao ChatGPT para gerar um script de migração.
Parecia bom à primeira vista. O script analisou o JSON, extraiu as informações de contato e as inseriu em um novo user_contacts mesa.
Por isso, eles fizeram-no.
Não há ensaio. Sem backup. Diretamente para a fase de preparação, que, como se verificou, partilhava dados com a produção através de uma réplica.
Algumas horas mais tarde, o apoio ao cliente começou a receber mensagens de correio eletrónico. Os utilizadores não estavam a receber notificações de pagamento. Outros tinham números de telefone em falta nos seus perfis. Foi então que nos telefonaram.
O que correu mal
O problema foi detectado no guião. Ele fez a extração básica, mas fez três suposições fatais:
- Não tratou de
NULL valores ou chaves em falta na estrutura JSON. - Introduziu registos parciais sem validação.
- Utilizou
ON CONFLICT DO NOTHING, pelo que quaisquer inserções falhadas foram silenciosamente ignoradas.
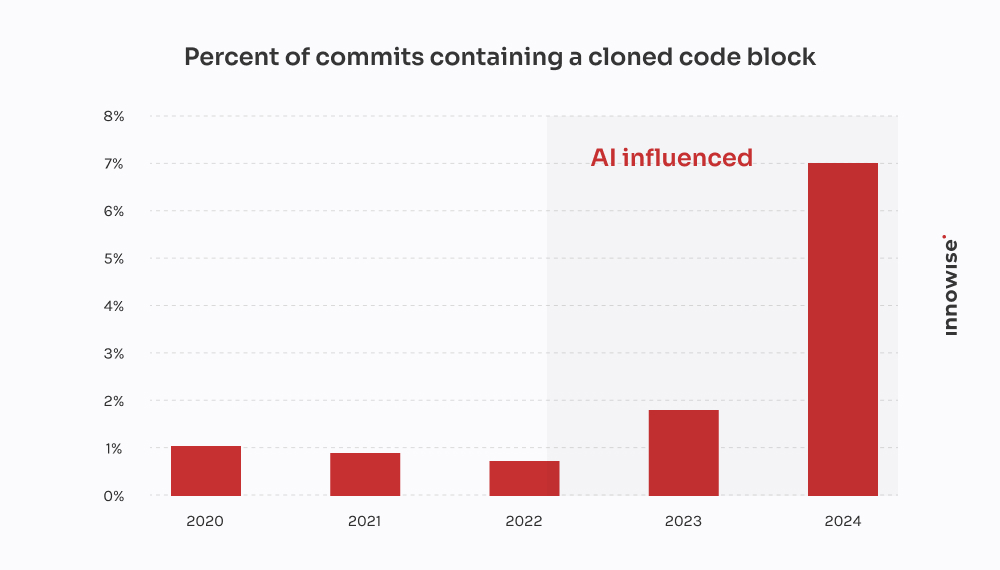
Resultado: sobre 18% dos dados de contacto foi perdido ou corrompido. Não há registos. Não há mensagens de erro. Apenas perda de dados silenciosa.
O que foi necessário para corrigir
Designámos uma pequena equipa para resolver a confusão. Eis o que fizemos:
- Diagnóstico e reprodução (4 horas) Recriámos o script num ambiente sandbox e executámo-lo contra um instantâneo da base de dados. Foi assim que confirmámos o problema e identificámos exatamente o que faltava.
- Auditoria forense de dados (8 horas) Comparámos o estado quebrado com as cópias de segurança, identificámos todos os registos com dados em falta ou parciais e comparámo-los com os registos de eventos para identificar quais as inserções que falharam e porquê.
- Reescrever a lógica da migração (12 horas) Reescrevemos todo o script em Python, adicionámos uma lógica de validação completa, criámos um mecanismo de reversão e integrámo-lo no pipeline de CI do cliente. Desta vez, ele incluiu testes e suporte a dry-run.
- Recuperação manual de dados (6 horas) Alguns registos não podiam ser recuperados das cópias de segurança. Extraímos os campos em falta de sistemas externos (as APIs do CRM e do fornecedor de correio eletrónico) e restaurámos manualmente os restantes.
Tempo total: 30 horas de engenharia
Dois engenheiros, três dias. Custo para o cliente: cerca de $4,500 em taxas de serviço.
Mas o maior impacto veio das consequências para os clientes. As notificações falhadas levaram à perda de pagamentos e ao abandono do serviço. O cliente disse-nos que gastou pelo menos $10,000 em bilhetes de suporte, compensação de SLA e créditos de boa vontade por causa de um script mal feito.
O mais irónico é que um programador sénior poderia ter escrito a migração correta em talvez quatro horas. Mas a promessa de velocidade AI acabou por custar-lhes duas semanas de limpeza e danos à reputação.
 Contrate-nos
Contrate-nos