 Anlita oss
Anlita oss


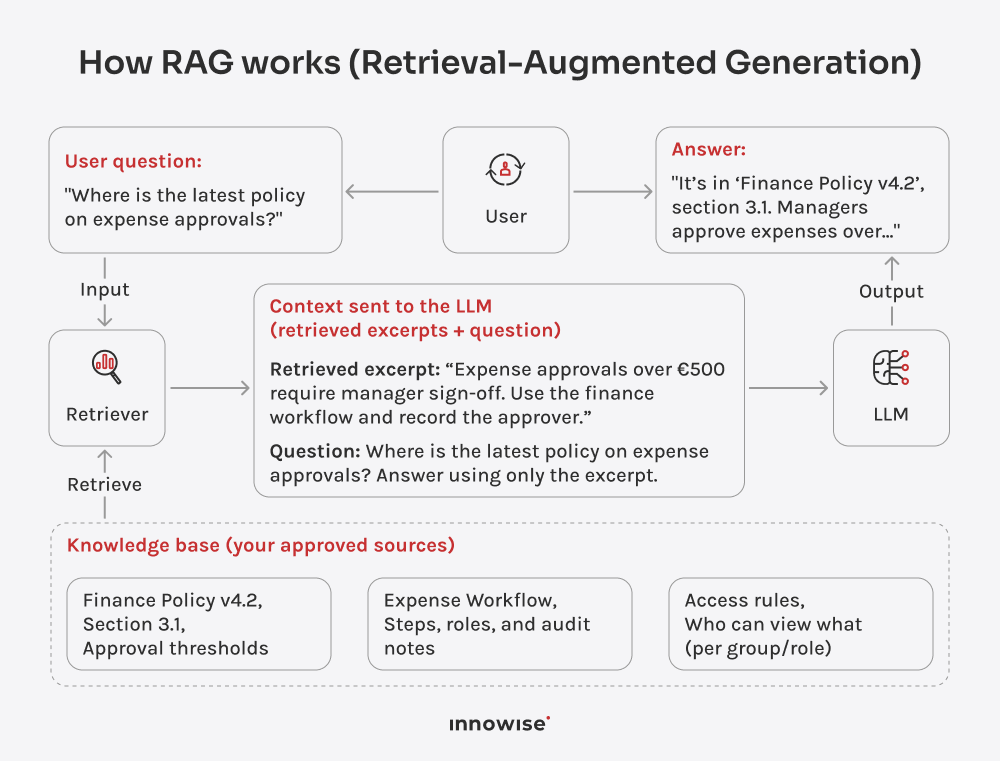
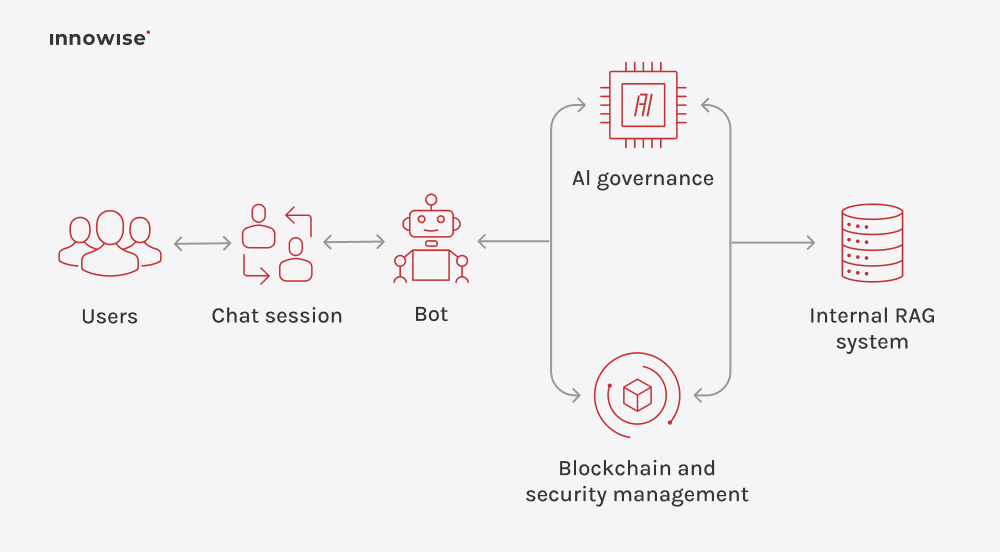
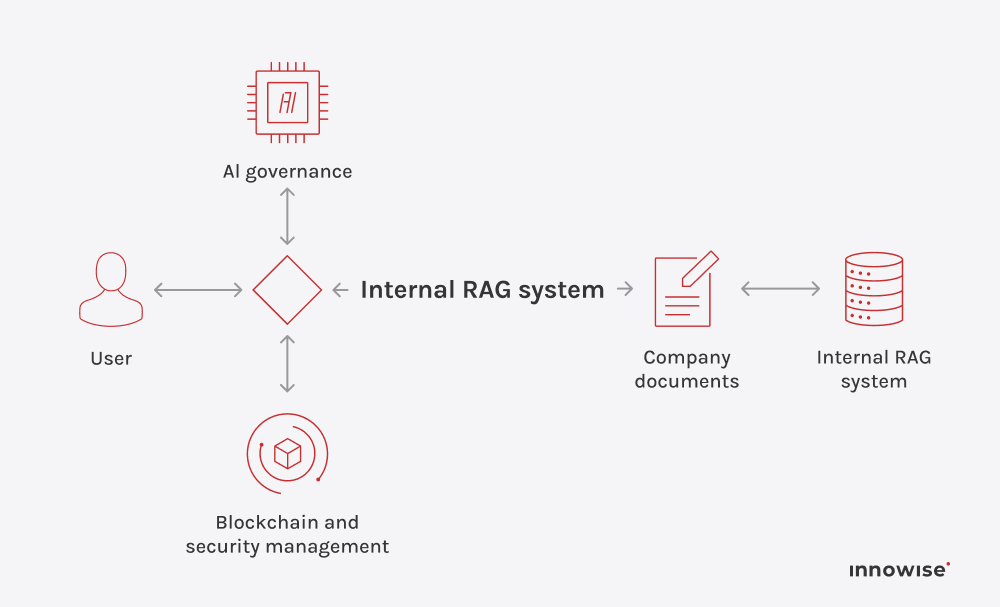
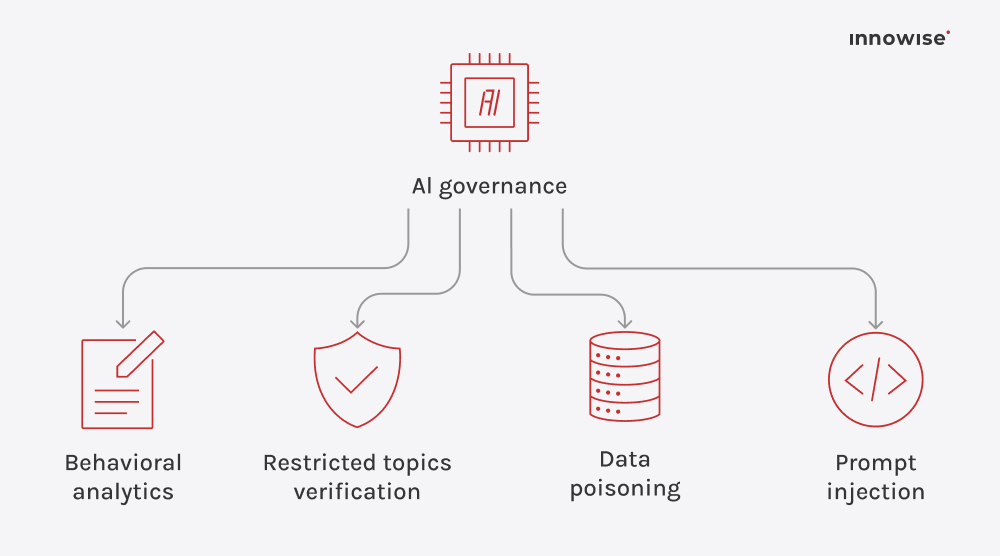


Den kan använda interna dokument, artiklar i kunskapsdatabasen, wiki-sidor, supportinnehåll och andra textkällor som du godkänner. Det viktiga är att du kontrollerar källorna och åtkomstreglerna.













Tack!
Ditt meddelande har skickats.
Vi behandlar din begäran och återkommer till dig så snart som möjligt.
