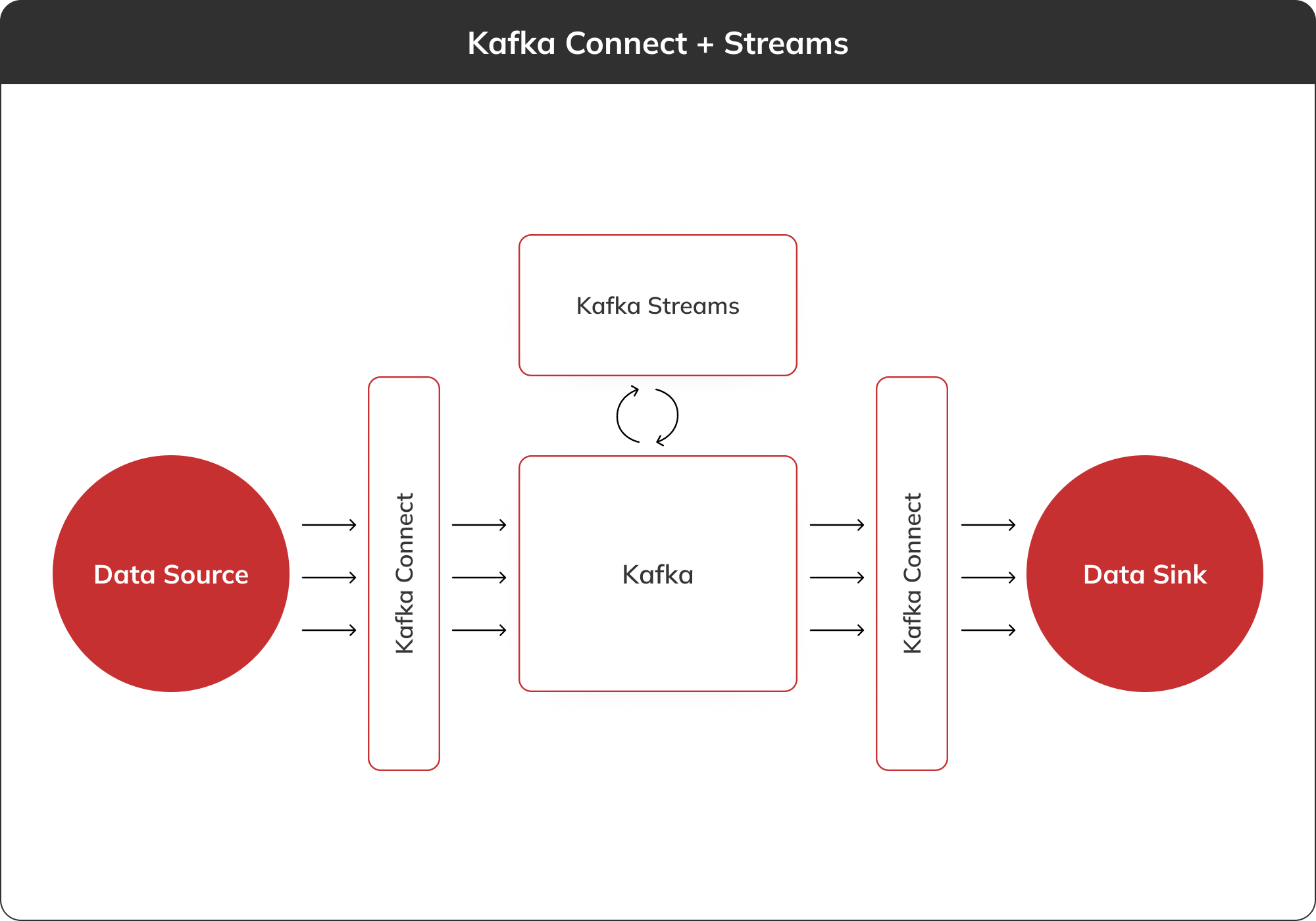
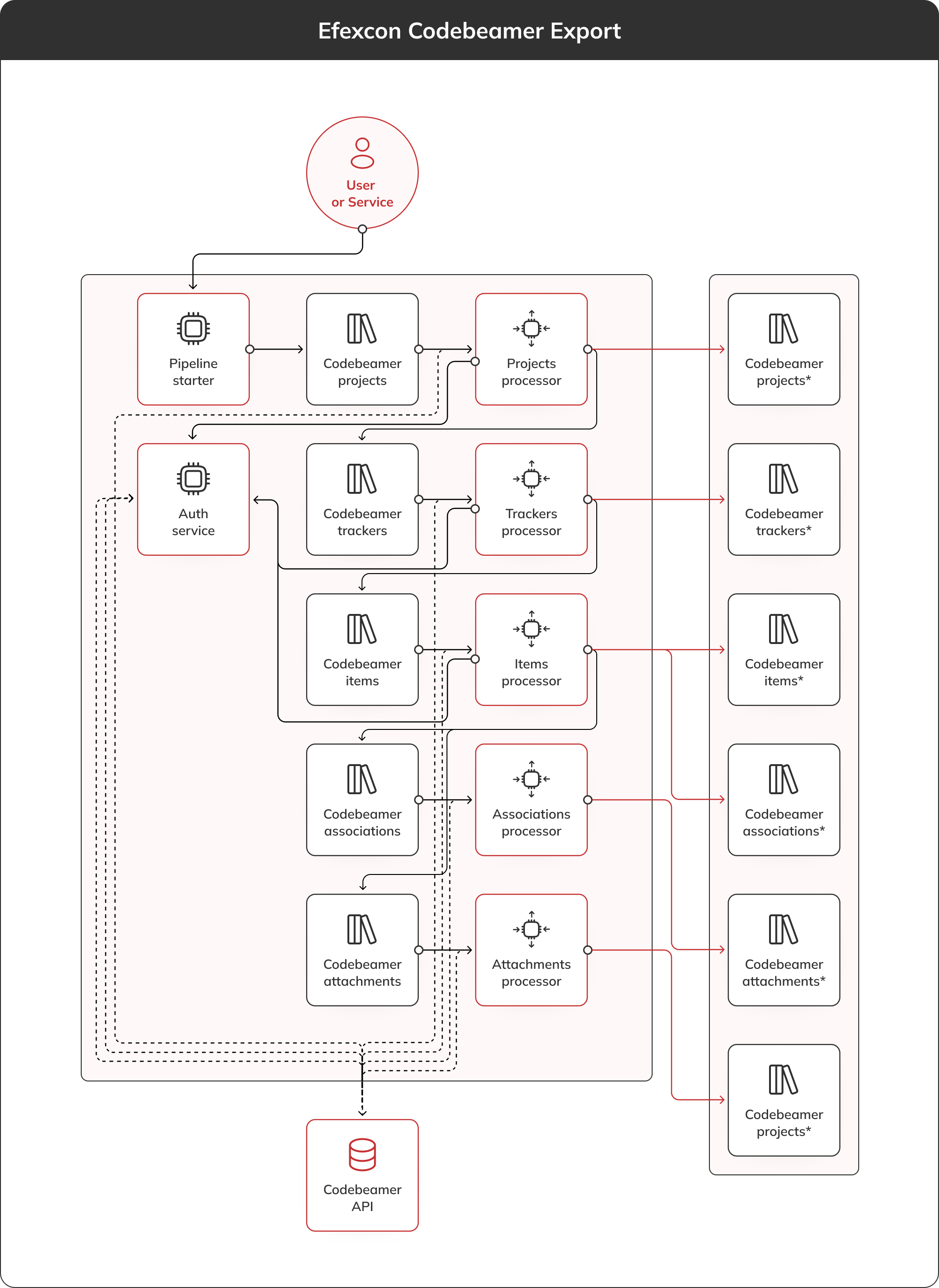
Lämna dina kontaktuppgifter, så skickar vi dig vår översikt via e-post
Jag samtycker till att mina personuppgifter behandlas för att skicka personligt marknadsföringsmaterial i enlighet med Integritetspolicy. Genom att bekräfta inlämningen samtycker du till att få marknadsföringsmaterial
Tack!
Formuläret har skickats in framgångsrikt.
Ytterligare information finns i din brevlåda.

Innowise is an international full-cycle software development company founded in 2007. We are a team of 3,500+ IT professionals developing software for other professionals worldwide.
Anlita dedikerade utvecklare
Anlita webbutvecklare
Anlita mobilutvecklare
Om oss
Tjänster
Teknik
Branscher
Portfölj
 Anställ
Anställ sv Svenska

Innowise is an international full-cycle software development company founded in 2007. We are a team of 3,500+ IT professionals developing software for other professionals worldwide.
Anlita mobilutvecklare