Legg igjen kontaktinformasjon, så sender vi deg oversikten vår på e-post
Jeg samtykker i å behandle personopplysningene mine for å sende personlig tilpasset markedsføringsmateriell i samsvar med Retningslinjer for personvern. Ved å bekrefte innsendingen samtykker du i å motta markedsføringsmateriell.
Takk skal du ha!
Skjemaet har blitt sendt inn. Mer informasjon finner du i postkassen din.
Innowise er et internasjonalt fullsyklus programvareutviklingsselskap grunnlagt i 2007. Vi er et team av IT fagfolk som utvikler programvare for andre fagfolk over hele verden.
Innowise er et internasjonalt fullsyklus programvareutviklingsselskap grunnlagt i 2007. Vi er et team av IT fagfolk som utvikler programvare for andre fagfolk over hele verden.
AI omformer dataprosesser: automatiserer kjedelige oppgaver som rensing, omforming og generering av data, slik at teamene kan fokusere på innsikt og strategi.
Dataarkitekturen er i rask utvikling: desentraliserte modeller (som Data Mesh) og enhetlige systemer (som Data Fabric) gjør datahåndteringen mer fleksibel og skalerbar enn noensinne.
Innsikt i sanntid er nå en nødvendighet: Virksomheter må behandle og reagere på data etter hvert som de kommer inn, for å holde seg konkurransedyktige og kunne reagere på umiddelbare muligheter eller risikoer.
-strategiene er i ferd med å diversifiseres: Hybrid- og multisky-miljøer gir virksomhetene den fleksibiliteten de trenger, men de krever også robust styring for å håndtere kompleksitet og kostnader.
Data er ikke lenger bare for analytikere: Selvbetjeningsverktøy, intuitive visualiseringer og automatisert innsikt gjør det mulig for ikke-tekniske team å ta datadrevne beslutninger. En slik datademokratisering er i ferd med å forandre driften i hele selskapet.
La meg starte med en dristig uttalelse: 2026r sannhetens år for big data-industrien dataindustrien. Vi har brukt det siste tiåret på å eksperimentere med all verdens skinnende ny teknologi: AI, IoT, skyplattformer og alle de andre moteordene. Men vet du hva? Det er på tide å stille opp, ellers går du glipp av båten. Hvis bedriften din ikke allerede er i gang med å finne ut hvordan du kan gjøre den enorme mengden data om til noe brukbart, kommer du til å bli akterutseilt.
2026 er tiden inne for å få disse verktøyene til å fungere for deg og ligge i forkant av utviklingen. Er du nysgjerrig på hvilke trender du bør holde øye med? La oss dykke ned i det.
Topp 15 + store datatrender som former 2026
I 2026, I takt med at stordata blir en viktig drivkraft for forretningsverdi, vil du se at det påvirker alle bransjer der ute. Fra AI-drevne analytiske copiloter til sanntids edge-prosessering - disse trendene definerer fremtiden for stordata som allerede er i ferd med å utfolde seg. De vil forme din forretningssuksess, så les denne artikkelen til siste slutt.
1. Generativ AI for datateknikk og analyse
En av de mest virkningsfulle fremtidige trender innen stordataanalyse er fremveksten av Generative AI. Selv om det ikke er perfekt ennå, tar GenAI allerede tak i de mest tidkrevende og kjedelige delene av datateknikk. AI vil ikke eliminere datakvalitetsutfordringene helt, men det kan redusere antall timer teamet ditt bruker på å klargjøre data betydelig.
AI integreres nå i datapipelines, og kan automatisere oppgaver som datarensing, fylling av manglende hull (imputering) og datatransformering. Dette betyr at du får rene, bruksklare data på en brøkdel av tiden. For eksempel kan plattformer som Databricks og Snowflake inkluderer allerede innebygd funksjonalitet for generative-AI-aktiverte pipelines. Det hjelper organisasjoner med å automatisere datatransformasjon, gap-fylling og levering av AI-klare datasett.
Profftips:
Begynn å integrere AI-verktøy i datapipelines for å automatisere rensing og transformasjon.
Invester i plattformer med generative AI-funksjoner for å fylle datahull og øke nøyaktigheten.
Oppmuntre datateamet til å fokusere på strategisk analyse ved å bruke AI-drevet innsikt til å ta raskere beslutninger.
Overvåk kontinuerlig AI-resultatene for å sikre datakvalitet og tilpasse dem til virksomhetens mål.
La oss utforske hvordan data kan løse forretningsutfordringene dine
2. Data Mesh + Data Fabric for å bygge ryggraden i dataarkitekturen
Å basere seg på utdaterte dataarkitekturer vil holde deg tilbake. Nøkkelen til å holde seg konkurransedyktig er å ta i bruk Data Mesh og Data Fabric.
Data Mesh desentraliserer dataeierskapet, slik at domeneteamene kan administrere og betjene sine egne data, og dermed slippe flaskehalsen med sentrale IT. Data Fabric kobler sammen alle datakilder (skyen, lokalt, edge) til et sammenhengende system med automatiserte metadata, lineage og integrasjon. Sammen skaper de en skalerbar, fleksibel arkitektur som gir smidighet uten at det går på bekostning av kontroll.
For å få dette til å fungere, må du begynne med å identifisere nøkkelområder i virksomheten som kan ta eierskap til sine egne data.
Implementer et metadatalag som sikrer at alle data er gjenfinnbare, kompatible og enkle å administrere.
Invester i verktøy og opplæring for å hjelpe domeneteamene med å ta fullt eierskap til dataene og unngå kaos.
Viktigst av alt er å fokusere på å fremme en kultur der data behandles som et produkt, med tydelig eierskap og samarbeid.
Mens Data Mesh definerer arkitektur for desentralisering, fungerer det best når det kombineres med en “data-som-produkt”-tankegang, der hvert datasett eies, dokumenteres og forvaltes som et ekte produkt.
3. Data som et produkt
Data Mesh gir deg strukturen. Data som et produkt gir deg disiplin. I 2026, Smarte selskaper desentraliserer ikke bare data, de håndterer dem også som et produkt, med tydelig eierskap, dokumentasjon og målbar verdi. Selv om mange selskaper fortsatt jobber med å sentralisere dataene sine, går trenden raskt bort fra data som ligger begravd i tilfeldige regneark eller isolerte databaser. I en data-som-produkt-tankegang har hvert datasett dokumentasjon, rolletildeling, servicenivåavtaler og en tilbakemeldingssløyfe for forbedring.
På denne måten vet markedsavdelingen hvor kampanjedataene deres befinner seg. Økonomifunksjonen stoler på inntektstallene uten å trenge en “dataavstemmingsdag”. Og ingeniørene slipper endelig å fungere som flaskehalsen mellom alle de andres dashbord.
Plattformer som Snowflake Data Cloud og Databricks Marketplace hjelper allerede team med å publisere, dele og til og med tjene penger på dataprodukter internt eller med partnere. Det åpner nye dører for samarbeid og nye inntektsstrømmer. Spesielt når “dataproduktet” ditt blir noe andre ønsker å kjøpe eller bygge videre på.
Profftips:
Tildel tydelig eierskap til alle større datasett, akkurat som du ville gjort for en produktfunksjon.
Definer hvem som er ansvarlig for kvalitet, dokumentasjon og oppetid.
Standardiser formater og bygg opp søkbarhet - en intern katalog der teamene kan “shoppe” etter datasett i stedet for å spørre Slack om lenker.
Til slutt kan du begynne å spore avkastningen på dataressursene: hvilke som genererer innsikt, besparelser eller inntekter.
"Hos Innowise sørger vi alltid for at data fungerer for deg på en praktisk og effektiv måte. Vår tilnærming integrerer AI, automatiserer dataarbeidsflyter og muliggjør innsikt i sanntid, slik at teamet ditt ikke blir overveldet av kompleksitet. Du får rene, handlingsrettede data når du trenger dem, slik at du kan ta beslutninger basert på fakta."
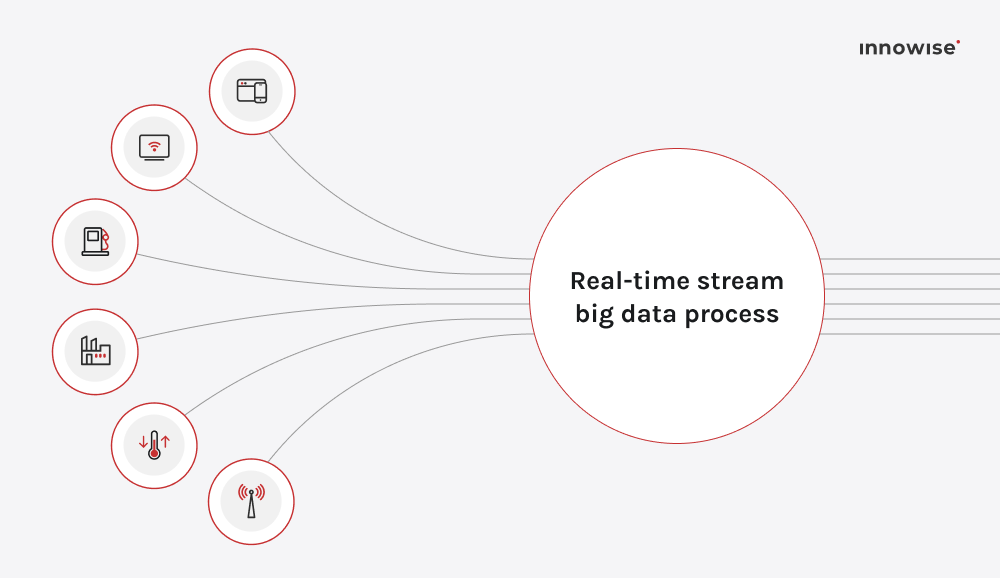
Den neste på listen over fremtidige trender innen stordata ersanntidsanalyse. Konseptet har vært under utvikling i mange år, men innen 2026 vil det raskt ha utviklet seg fra å være et konkurransefortrinn til å bli et grunnleggende nødvendighet for organisasjoner som krever øyeblikkelig innsikt. Når du behandler data i det øyeblikket de kommer inn, i stedet for å vente på batcher, får du muligheten til å handle på hendelser, signaler og mønstre. når de skjer. For stordata-arenaen betyr dette strømming av datakilder med store volumer (IoT-sensorer, brukerinteraksjoner, logger) gjennom pipelines som analyserer og reagerer i løpet av sekunder eller millisekunder.
Markedet støtter dette skiftet. Den globale sektoren for strømmeanalyse ble verdsatt til $23,4 milliarder i 2023 og forventes å vokse til rundt $ 128,4 milliarder innen 2030, med en CAGR på omtrent 28,3% mellom 2024 og 2030.Bransjer som finans, telekom, produksjon og detaljhandel bruker allerede strømbaserte modeller til å oppdage svindel, dynamisk prising, prediktivt vedlikehold og optimalisering av kundeopplevelsen.
Profftips:
Identifiser ett eller to tilfeller med stor innvirkning der forsinkelser koster penger eller konkurransefortrinn (f.eks. lagerendringer, svindeltopper, utstyrssvikt).
Implementer et proof-of-concept for strømmeanalyse ved hjelp av teknologier som Apache Kafka, Flink eller administrerte tjenester fra skyleverandører.
Sørg for at arkitekturen din er bygget for kontinuerlig inntak og evaluering, inkludert varsling, dashbord og automatiserte utløsere.
Etabler SLA-er for styring, datakvalitet og ventetid for disse strømmene, ettersom hastighet bare gir verdi hvis innsikten er pålitelig og brukbar.
Hvis datastrategien din fortsatt behandler sanntid som noe “ekstra” og fokuserer sterkt på batch først, 2026 vil fremheve gapet, tro meg.
5. Grafanalyse og kunnskapsgrafer for å avdekke skjulte sammenhenger
Grafanalyse kommer i søkelyset i 2026, ikke som en ny teknologi, men fordi integrasjonen med AI akselererer innføringen av den. I stedet for å behandle data utelukkende som rader og kolonner, bruker organisasjoner grafer for å forstå hvordan enheter kobles sammen: kunder, produkter, sensornoder, svindelringer og så videre. Kunnskapsgrafer og grafdatabaser gjør dette mulig: De kartlegger komplekse sammenhenger og avdekker innsikter som tradisjonelle metoder sliter med å få frem. For eksempel kan en fersk grafdatabaserapport fra Verified Market Reports forklarer at grafdatabaser nå er avgjørende for sanntidsbehandling, semantiske relasjoner og AI-drevet anomalideteksjon.
For bedriftsledere er den viktigste fordelen denne: Du avdekker hvorfor ting skjer, ikke bare at de skjer. Når det gjelder svindeloppdagelse, oppdager du nettverket av aktører, når det gjelder anbefalinger, kartlegger du skjulte forbindelser, og når det gjelder IoT, sporer du kjeder av feil. Denne kraften gir dypere innsikt, raskere deteksjon, og mer strategisk handling.
Profftips:
Identifiser et domene der relasjoner er viktige (kunde-360, leverandørkjede, svindel eller IoT).
Piloter en grafmodell ved hjelp av en grafdatabase, eller utvid datasjøen med et kunnskapsgraflag.
Sørg for at teamet ditt lager tydelige enhets- og relasjonsdefinisjoner (noder og kanter), og sørg for at de inkluderer lineage og styring, slik at innsikten forblir troverdig.
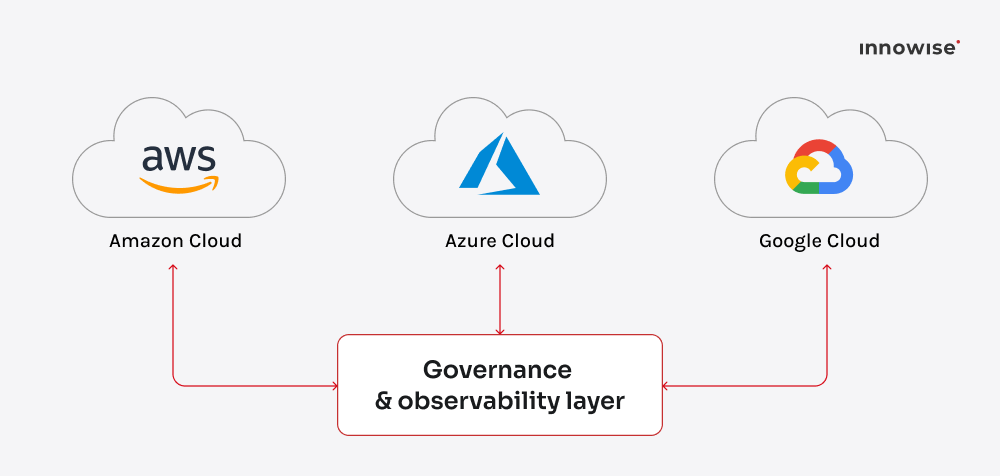
6. Multi-sky og hybride datastrategier
I 2026 blir det i økende grad sett på som en risiko å stole utelukkende på én enkelt skyleverandør, på samme måte som å plassere alle investeringene i én enkelt aksje. Selv om mange organisasjoner fortsatt primært bruker én plattform, spiller de mest strategisk avanserte selskapene nå multisky-spillet. De balanserer tjenester fra AWS, Azure og Google Cloud for å unngå innlåsing og få det beste forholdet mellom ytelse og kostnad ut av hver av dem.
Hybride oppsett øker også. Her kombinerer organisasjoner skytjenester med sine eksisterende lokale datasentre. Årsakene til denne hybride tilnærmingen går dypere enn bare å beholde sensitive data lokalt:
Regional etterlevelse: Oppfyllelse av spesifikke lover (som GDPR) som pålegger at visse data må forbli innenfor landets grenser.
Eldre systemer: Fortsette å bruke høytytende, ikke-migrerbare eldre systemer eller mainframes som er kritiske for kjernevirksomheten.
Avkastning på kapitalinvesteringer: Maksimerer avkastningen på tidligere betydelige investeringer i lokal maskinvare og infrastruktur.
Haken? Kompleksitet. Spredning av arbeidsbelastninger på tvers av skyer introduserer flere bevegelige deler: forskjellige API-er, faktureringssystemer og styringsregler. Vinnerne er de som automatiserer orkestrerings- og overvåkingslaget. Tenk spørringsmotorer på tvers av skyer, enhetlig identitetsadministrasjon og observasjonsverktøy som sporer ventetid og kostnader i sanntid.
Profftips:
Kartlegg arbeidsmengdene dine, og merk hva som virkelig drar nytte av flere skyer: analyse, lagring eller databehandling.
Bruk skyagnostiske arkitekturer som bygger på åpne formater som Parquet, Delta eller Iceberg.
Ta i bruk FinOps-verktøy for å overvåke utgiftene på tvers av leverandører og unngå “regningssjokk”.
Hold styringen sentral: én tilgangspolicy, ett revisjonsspor, én oversikt over datarekkefølgen, uansett hvor dataene befinner seg.
Generiske dataplattformer er flotte. Helt til de begynner å løse noe spesielt. Dette er grunnen til at vi i 2026, I dag er selskaper i konkurranseutsatte, risikoutsatte eller regulerte bransjer ferdige med generiske verktøy. De vil ha bransjetilpassede løsninger som snakker deres språk, håndterer deres regelverk og leverer resultater i stedet for instrumentpaneler som ser imponerende ut, men som betyr lite.
Så hvorfor etterspør bedriftene plutselig disse spesialiserte løsningene i 2026? Det koker egentlig ned til tre store ting:
Regulatorisk press: For å overholde lover og regler uten spesialtilpasset koding, trenger bedrifter løsninger med styringsrammeverk som allerede er tilpasset deres spesifikke sektor.
AI-drevne domenemodeller: Fordi AI ikke er bedre enn opplæringen, trenger organisasjoner løsninger som leveres med forhåndsopplært domeneekspertise og vokabular for å sikre nøyaktig innsikt.
Etterspørsel etter forhåndsbygget kompetanse: Organisasjoner er lei av å kaste bort tid og penger på å lære generiske verktøy hvordan deres bransje fungerer. De vil ha løsninger med ferdigpakkede koblinger, dataordbøker og compliance-rammeverk som passer rett inn i den daglige arbeidsflyten. Alt handler om å oppnå resultater og eliminere det smertefulle og kostbare oversettelsestrinnet.
Det er derfor markedet beveger seg mot domenespesifikke dataprodukter: forhåndsbygde modeller, koblinger og compliance-rammeverk som passer rett inn i reelle arbeidsflyter. Denne spesialiseringen viser allerede massiv vekst i vertikale markeder. Ifølge Visiongain er for eksempel markedet for helseanalyse alene vil nå $101 milliarder kroner innen 2031, drevet av denne typen spesialisering.
Profftips:
Slutt å jakte på analyseplattformer som passer for alle. Gjør det i stedet, Velg verktøy som er utviklet for din bransjes dataegenskaper: fra EMR-standarder i helsevesenet til AML-regler i banksektoren.
Press leverandørene på domeneekspertise, ikke bare på den tekniske stakken.
Bygg opp små, resultatdrevne piloter rundt de største operasjonelle smertepunktene, og skaler det som faktisk fungerer.
8. Edge computing for stordata
I 2026, er kravet om umiddelbar, automatisert handling avgjørende. Selv om skyen fortsatt er viktig, innser bedriftene at det koster for mye tid og penger å sende hver eneste byte av data til en ekstern server for behandling.
Edge computing er løsningen. Det bringer databehandlingen nærmere der den genereres: sensorer, maskiner, enheter og til og med biler. I stedet for å sende terabyte med data over nettverket, kan du behandle de viktige dataene lokalt og handle umiddelbart.
Hvorfor eksploderer denne trenden nå?
IoT-eksplosjon: Milliarder av sensorer betyr at sentralisert behandling er for dyrt og tregt.
Edge AI: Med de lette modellene kan AI ta avgjørelser i sanntid direkte på enheten, og dermed hoppe over forsinkelsen i skyen.
Mandat i sanntid: På områder der mye står på spill (som å fange opp utstyrsfeil), er det millisekunder som teller.
Dette er viktigst for bransjer der hastighet er livsviktig: smarte fabrikker som justerer produksjonslinjene underveis, sykehus som overvåker pasienter i sanntid, eller butikkjeder som styrer prisene dynamisk basert på lokal etterspørsel. Og det er penger i det: IDCs prognoser globale utgiftene til edge computing-løsninger vil vokse med ~13,8% CAGR og nå nesten $380 milliarder innen 2028.
De smarteste organisasjonene erstatter ikke skyen, de kompletterer den. De bruker et hybridoppsett: lokal prosessering for hastighet, skylagring for skala. Resultatet er fantastisk: lavere ventetid, reduserte båndbreddekostnader og raskere beslutninger som faktisk flytter nålen.
Profftips:
Begynn med ett område der ventetid er et problem. Det kan være kvalitetskontroll i produksjonen eller prediktivt vedlikehold i logistikken.
Implementer edge-analyse der, og koble den til det sentrale skysystemet.
Definer klare regler for hva som skal behandles lokalt og hva som skal behandles sentralt, og sørg for at styringen er konsekvent i begge tilfeller.
9. Syntetiske data og personvernfremmende teknologi
I 2026, Det er vanskeligere enn noensinne å få tilgang til data fra den virkelige verden: Personvernlovene er strengere, tilsynsmyndighetene er på vakt, og brukerne er langt mindre tilgivende. Derfor trenger vi syntetiske data.
Trenden eksploderer nå fordi GenAI bom har endelig gjort syntetiske data av høy nok kvalitet til å etterligne kompleks informasjon fra den virkelige verden på en pålitelig måte. Bedrifter er i økende grad avhengige av disse kunstige, statistisk nøyaktige dataene for å trene opp massive AI-modeller raskere og billigere enn med tradisjonelle metoder, samtidig som de automatisk oppfyller strenge krav til etterlevelse av GDPR og EUs AI-lov.
Syntetiske dataverktøy finnes overalt: fra finansfirmaer som trener opp modeller for å oppdage svindel, til helseforetak som kjører AI-diagnostikk uten å eksponere pasientdata. Gartner forventer at det innen 2030, syntetiske data vil overgå reelle data i AI-opplæringen, fordi det er tryggere, raskere og enklere å skalere.
Profftips:
Bruk syntetiske data på områder der compliance blokkerer tilgangen til ekte informasjon (helsevesen, finans eller HR-analyse).
Integrer PET-teknologier (Privacy-Enhancing Technologies) tidlig i pipelinen, ikke som en ettertanke.
Kjør pilotprosjekter som sammenligner modellens ytelse på syntetiske og reelle data, og følg med på hvordan det påvirker nøyaktighet og skjevhet.
Ta kontroll over dataene dine - reduser kostnadene, øk effektiviteten
I 2026, Endelig føles analyse menneskelig. AI copiloter og narrative visualiseringsverktøy gjør nå data om til tydelige historier i stedet for endeløse diagrammer. Verktøy som Power BI Copilot, Tableau GPT, camelAI, og Lookers GenAI-lag kan spørre, oppsummere og forklare innsikt på et enkelt språk.
Tenk på dem som dataanalytikeren din. Du kan spørre: “Hvordan utviklet omsetningen seg dette kvartalet?” eller “Hvilken kampanje ga høyest avkastning på investeringen?” og få umiddelbare svar i klartekst. Verktøy som Power BI Copilot, Tableau GPT, og kamelAI allerede gjør dette, og kobler store språkmodeller direkte til bedriftens data.
Profftips:
Integrer copiloter i analysestakken, koble dem til verifiserte datasett, og redesign instrumentpaneler med utgangspunkt i fortellinger, ikke målinger.
Lær opp teamene til å validere resultatene fra AI og fokusere på “hvorfor” bak hvert tall.
11. Cloud datalagring og fremveksten av lakehouse
I 2026, har grensen mellom datasjøer og datavarehus blitt visket ut. Den nye standarden er lakehouse architecture, som er en hybridmodell som kombinerer skalerbarheten til datasjøer med strukturen og ytelsen til datavarehus. Du kan lagre ustrukturerte data, søke i dem med SQL og kjøre maskinlæring. Alt på ett sted. Uten å sjonglere med ti forskjellige plattformer.
Leverandører som Databricks, Snowflake, og Google BigQuery er de som leder an her.
Profftips:
Hvis infrastrukturen din fortsatt deler data mellom ulike datasjøer og datalagre, bør du begynne å konsolidere.
Ta i bruk en lakehouse-løsning som passer til stakken din, og lær opp teamet ditt til å søke i både strukturerte og ustrukturerte datasett.
Prioriter åpne formater som Parkett og Delta Lake for å unngå leverandørinnlåsing.
Og når du først er i gang, kan du begynne å legge avanserte analyser og maskinlæring direkte på toppen. Det er der den virkelige avkastningen ligger.
12. Dataobserverbarhet og DataOps
I 2026, Å administrere datapipelines uten observerbarhet er som å fly et fly med dashbordet slått av. Du beveger deg kanskje raskt, men du har ingen anelse om hva som går i stykker. Dataobservabilitet er hvordan teamene får innsyn i dataenes tilstand, friskhet og pålitelighet. Det forteller deg når noe er galt, hvorfor det skjedde, og hvordan du kan fikse det før dashbordene begynner å vise tull og tøys.
Så hvorfor er dette viktig nå? Fordi du ikke kan ha styring eller etterlevelse uten det.
Du må styre: Observability-verktøy sporer hele datareisen (eller -linjen), og gir deg bevisene du trenger for å håndheve kvalitetsstandarder og retningslinjer i hele bedriften.
Du må overholde dette: Siden verktøyene logger alt (hvem som har rørt dataene, hvordan de ble behandlet), genererer de det nøyaktige revisjonssporet som kreves for å tilfredsstille lovgivere (for eksempel i forbindelse med GDPR).
Dette går hånd i hånd med DataOps, som automatiserer ting som testing og distribusjon. Sammen gir observabilitet og DataOps deg en pålitelig, kompatibel og bunnsolid datagrunnmur med færre overraskelser og raskere gjenopprettingstid.
Profftips:
Begynn med å instrumentere de viktigste datarørledningene dine med observasjonsverktøy som sporer ferskhet, opphav og avvik.
Behandle datarørledninger som produksjonssystemer, og overvåk dem kontinuerlig, ikke bare når noe går i stykker.
Koble sammen observerbarhet med DataOps-praksis: automatiser testing, implementer versjonskontroll for transformasjoner, og skap et tydelig eierskap til hvert datasett.
13. FinOps for data og AI
Har du noen gang ligget våken om natten på grunn av skyregninger? Etter hvert som datamengdene eksploderer og AI-arbeidsbelastningen mangedobles, FinOps (økonomiske operasjoner for sky og data) blir avgjørende. Målet er enkelt: forstå hvor hver eneste krone i dataøkosystemet ditt går, og sørg for at den faktisk går til å kjøpe forretningsverdi, ikke bare større servere.
Opplæring av store modeller, lagring av petabytes med data og kjøring av endeløse spørringer kan fort tære på budsjettene. FinOps-team bruker nå analyse og automatisering til å spore kostnader i sanntid, oppdage ineffektivitet og forutsi bruk på tvers av avdelinger. Cloud-leverandører tilbyr til og med egne verktøy for dette (AWS Cost Explorer, Google Cloud Billing, Azure Cost Management), men den virkelige gevinsten kommer ved å integrere økonomiske beregninger direkte i dataarbeidsflytene dine.
Profftips:
Få FinOps tidlig inn i datastrategien.
Merk alle datasett, rørledninger og modeller etter kostnadssenter og bedriftseier.
Spor utgifter til lagring, databehandling og AI-opplæring med dashbord i sanntid.
Oppfordre datateamene til å overvåke ressursbruken like nøye som de overvåker ytelsesmålingene.
Og når du er i tvil, automatiser. Bruk AI-drevne anbefalinger for å stenge ned inaktive klynger eller rebalansere arbeidsbelastninger.
14. Forklarlig og ansvarlig AI
I 2026, AI styrer så mye av virksomheten at “bare stol på modellen” ikke holder lenger. Styrer, tilsynsmyndigheter og kunder forventer alle åpenhet. De ønsker å vite hvorfor en algoritme tok en beslutning, ikke bare resultatet. Det er derfor Explainable AI (XAI) og Ansvarlig AI får stadig større gjennomslagskraft. Sammen gjør de maskinlæring til en mindre svart boks og mer til et system du kan styre.
Bankene bruker allerede forklaringsmodeller for å begrunne kredittbeslutninger overfor revisorer. Helsepersonell er avhengige av dem for å vise hvordan diagnostiske algoritmer kommer frem til konklusjoner. Til og med HR-systemer er under lupen for å bevise at ansettelsesanbefalinger er rettferdige. Når beslutninger påvirker mennesker eller fortjeneste, er blind tillit til AI ikke en strategi, det er en risiko.
Profftips:
Sette opp interne retningslinjer for forklarbarhet på tvers av alle AI-prosjekter.
Krev at alle modeller har en klar begrunnelse for sine prediksjoner og en oversikt over treningsdataene.
Bruk forklaringsverktøy som SHAP, LIME, eller skyleverandørens egne XAI-funksjoner.
Og gjør ansvar til en del av arbeidsflyten: inkluder juridiske, compliance- og HR-ansvarlige i styret for AI.
15. Multimodal analyse
Innen 2026, utvikling av stordata vil gå fra tabeller og dashbord til en ny æra med multimodale analyser. Her kombineres tekst, bilder, video og sensordata for å skape et komplett, kontekstrikt bilde. I stedet for å analysere tilbakemeldinger fra kunder og salgstall hver for seg, kan teamene nå korrelere transkripsjoner av samtaler, produktbilder og brukeratferd i ett og samme arbeidsområde.
Høres ut som sci-fi, ikke sant? Men plattformer som Databricks MosaicML, Anthropics Claude for data, og OpenAIs GPT-4 Turbo med visjon allerede håndterer datainput i flere formater. Resultatet er kult. Kontekstrik innsikt føles nesten intuitiv. Tenk deg at du kan forutsi feil på utstyret ved å kryssanalysere vibrasjonslogger, termiske bilder og vedlikeholdsnotater. Det er det multimodal analyse muliggjør.
Profftips:
Kartlegg hvor dataene dine befinner seg, og hvor fragmenterte de er på tvers av formater.
Hvis analysene dine bare fokuserer på strukturerte data, kan du begynne å legge til ustrukturerte kilder: kundesamtaler, bilder og videofeeder.
Invester i en plattform som støtter multimodal input, helst en som er bygget med vektordatabaser og semantiske søk.
Og viktigst av alt: Oppmuntre teamene til å tenke utover tallene.
Forenkle dataarbeidsflyten og åpne for nye muligheter
Og den siste på listen over viktige trender innen stordata er beslutningsintelligens (DI). Det blander datavitenskap, DI-systemer kombinerer analyse, psykologi og forretningslogikk for å hjelpe organisasjoner med å ta smartere beslutninger raskere. I stedet for å slenge hundrevis av beregninger etter deg, modellerer DI-systemene hvordan valg fører til resultater, og simulerer deretter scenarier før du forplikter deg.
Tenk på det som en analyse som gir svar på “Hva skjer hvis vi faktisk gjør dette?”, ikke bare “Hva skjedde i forrige kvartal?” Detaljhandlere bruker det til å teste prisstrategier før lansering. Banker bruker det til å simulere risikoeksponering på tvers av porteføljer. Til og med HR-team bruker DI til å forutsi effekten på ansettelser og lojalitet før retningslinjene settes i drift.
Markedet viser dette skiftet: det globale markedet for beslutningsintelligens ble estimert til $15,22 milliarder kroner i 2024 og forventes å nå $36,34 milliarder innen 2030, og vokser med en CAGR på rundt 15,4%.
Profftips:
Begynn med å kartlegge hvordan beslutningene tas: hvem som tar dem, hvilke data de bruker, og hvordan suksess måles.
Identifiser deretter områder med gjentakende eller høy innsats der simulering kan forhindre feil.
Prøv ut et DI-verktøy som kobler forretningslogikk med sanntidsdata, og definer KPI-er for beslutningsresultater, ikke bare datanøyaktighet.
Avslutning
Så hva er fremtiden for stordata? 2026 bringer med seg et nytt modenhetsnivå. Nå ligger fokuset på å velge verktøy og metoder som faktisk skaper effekt. Virksomheter som kobler teknologi med klare mål, vil oppleve raskere vekst og sterkere resultater.
Bruk AI der det sparer tid og forbedrer nøyaktigheten. Bygg et datanettverk som hjelper teamene med å jobbe sammen i stedet for i siloer. Invester i sanntidsanalyser som hjelper deg med å handle i rett øyeblikk, ikke i etterkant.
Årets ledere forstår én ting: Verdien kommer fra målrettet bruk av data. Velg det som passer til strategien din, få det til å fungere på tvers av teamene, og la data bli motoren som driver alle smarte grep du gjør.
Philip har et skarpt fokus på alt som har med data og AI å gjøre. Han er den som stiller de riktige spørsmålene tidlig, setter en sterk teknisk visjon og sørger for at vi ikke bare bygger smarte systemer - vi bygger de riktige, for å skape reell forretningsverdi.
Et dypdykk i rollen som Frontier Deployment Engineer og hvordan FDE-er forvandler eksperimentelle AI-piloter til sikre, målbare og skalerbare AI-produksjonssystemer.

 Lei oss
Lei oss