 Lei oss
Lei oss


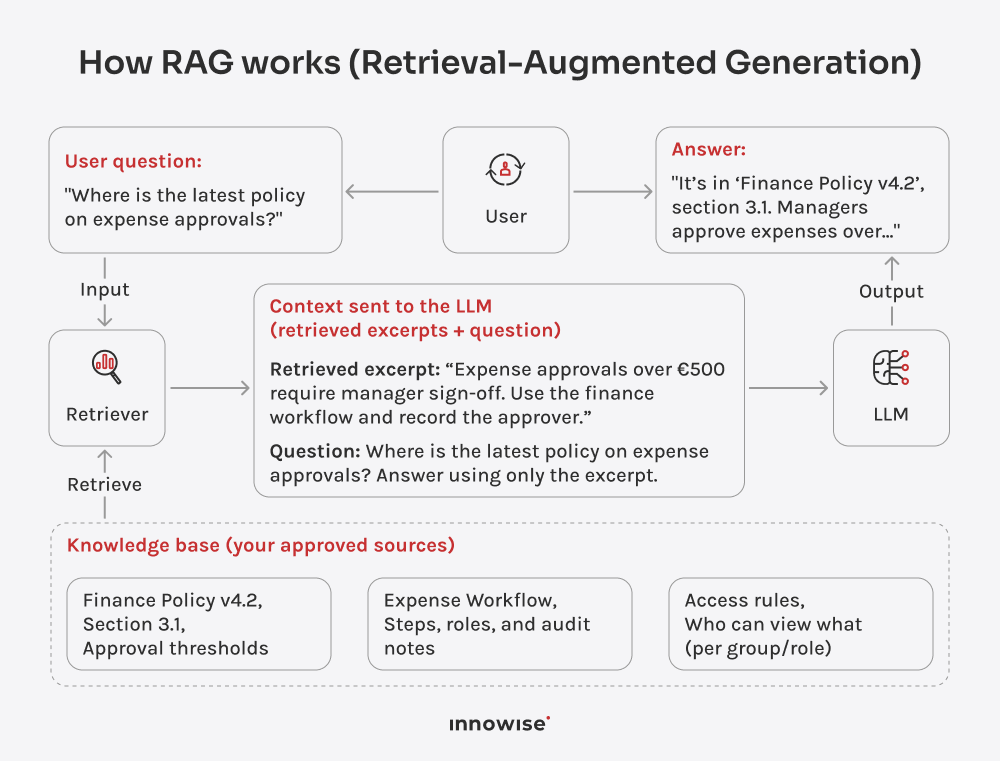
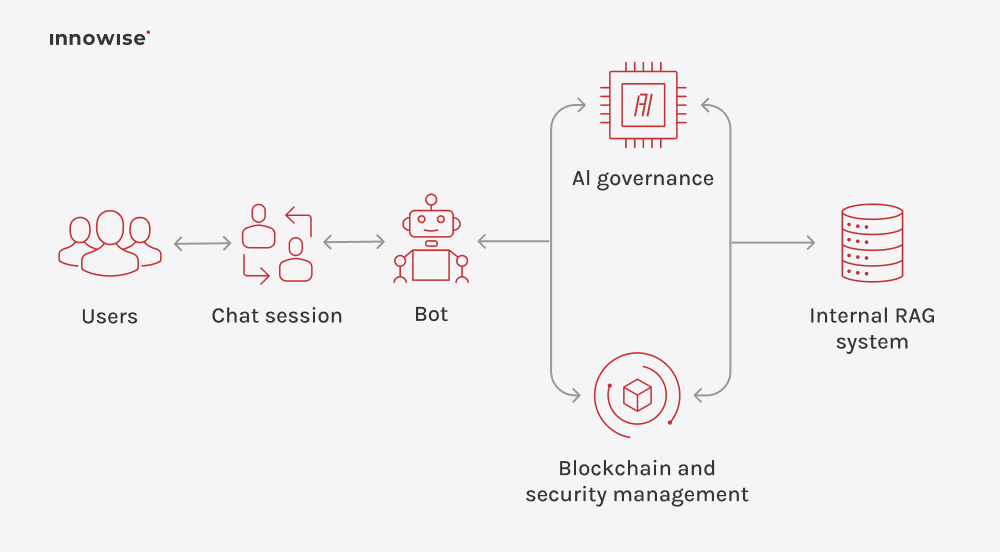
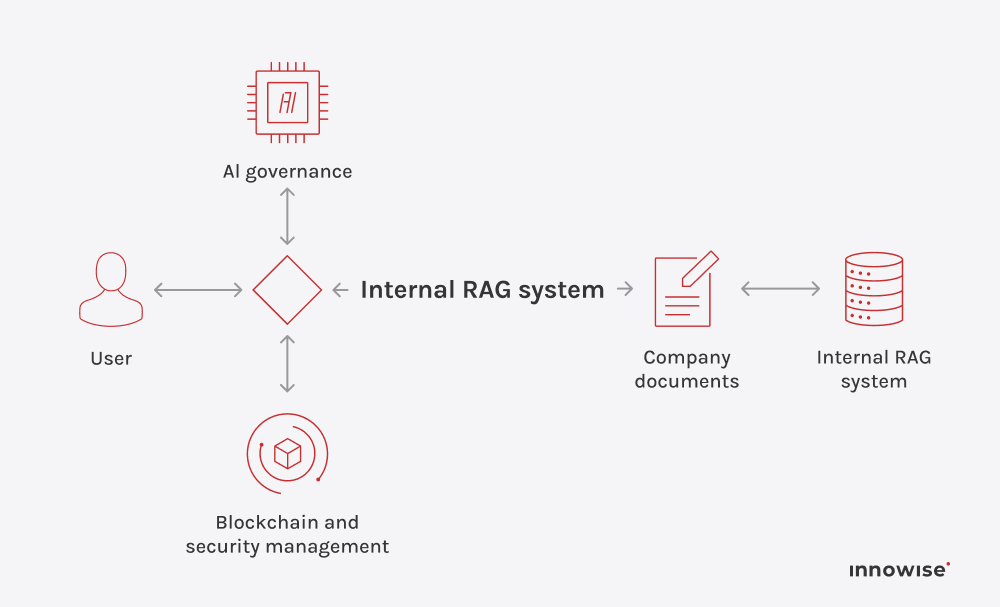
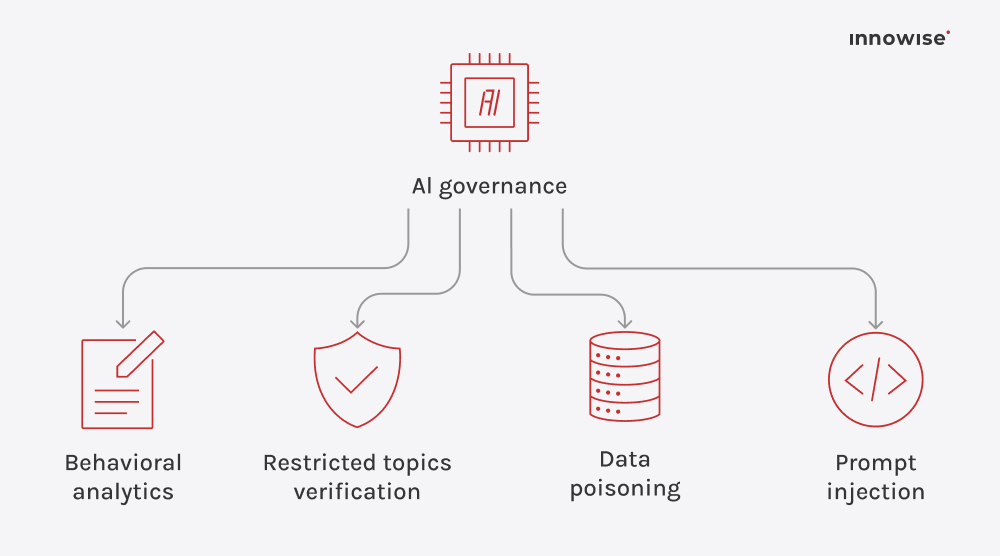


Den kan bruke interne dokumenter, artikler i kunnskapsbaser, wikisider, supportinnhold og andre tekstkilder du godkjenner. Det viktigste er at du kontrollerer kildene og tilgangsreglene.












Takk skal du ha!
Meldingen din er sendt.
Vi behandler forespørselen din og kontakter deg så snart som mulig.

