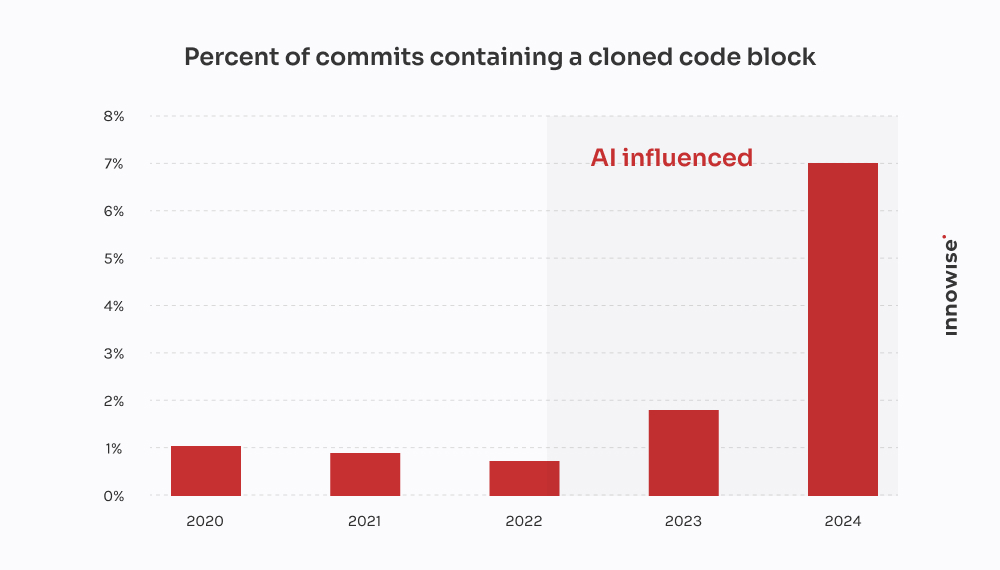
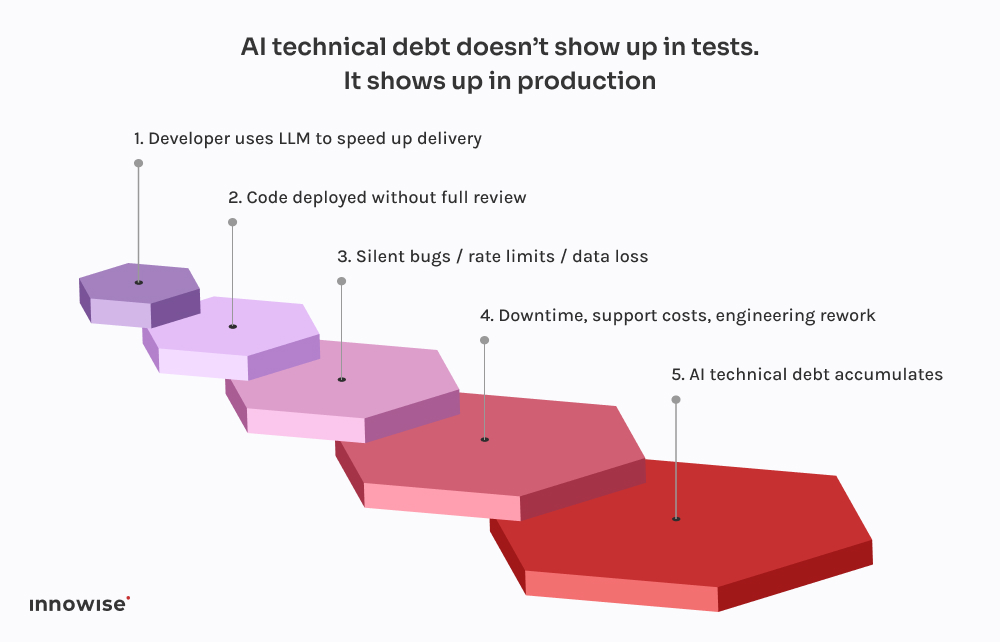
Tämä tuli nopeasti kasvavalta fintech-yritykseltä.
He olivat ottamassa käyttöön uutta versiota asiakastietomallistaan jakamalla yhden suuren JSONB-kentän Postgresissä useisiin normalisoituihin taulukoihin. Aika tavallista tavaraa. Mutta koska aikataulu oli tiukka ja käsiä ei ollut tarpeeksi, yksi kehittäjistä päätti "nopeuttaa asioita" pyytämällä ChatGPT:tä luomaan siirtoskriptin.
Se näytti päällisin puolin hyvältä. Skripti purki JSON-tiedot, poimi yhteystiedot ja lisäsi ne uuteen user_contacts pöytä.
Niinpä he juoksuttivat sitä.
Ei kuivaharjoittelua. Ei varmuuskopiointia. Suoraan stagingiin, joka, kuten kävi ilmi, jakoi tietoja tuotannon kanssa kopion kautta.
Muutamaa tuntia myöhemmin asiakastuki alkoi saada sähköposteja. Käyttäjät eivät saaneet maksuilmoituksia. Toisten profiileista puuttui puhelinnumeroita. Silloin he soittivat meille.
Mikä meni pieleen
Jäljitimme ongelman käsikirjoitukseen. Se suoritti perusuuttamisen, mutta se teki kolme kohtalokasta oletusta:
- Se ei käsitellyt
NULL arvoja tai puuttuvia avaimia JSON-rakenteen sisällä. - Se lisäsi osittaisia tietueita ilman validointia.
- Se käytti
ON CONFLICT DO NOTHING, joten kaikki epäonnistuneet lisäykset jätettiin hiljaisesti huomiotta.
Tulos: noin 18% yhteystiedoista oli joko kadonnut tai vioittunut. Ei lokitietoja. Ei virheilmoituksia. Vain hiljainen tietojen menetys.
Mitä korjaaminen vaati
Lähetimme pienen ryhmän selvittämään sotkua. Teimme näin:
- Diagnoosi ja replikaatio (4 tuntia) Loimme skriptin uudelleen hiekkalaatikkoympäristössä ja ajoimme sen tietokannan tilannekuvaa vastaan. Näin varmistimme ongelman ja kartoitimme tarkalleen, mitä puuttui.
- Rikostekninen tietojen tarkastus (8 tuntia) Vertasimme rikkinäistä tilaa varmuuskopioihin, tunnistimme kaikki tietueet, joista puuttui tai joissa oli osittaisia tietoja, ja vertasimme niitä tapahtumalokeihin jäljittääksemme, mitkä lisäykset epäonnistuivat ja miksi.
- Siirtymislogiikan uudelleenkirjoittaminen (12 tuntia) Kirjoitimme koko skriptin uudelleen Python:llä, lisäsimme täyden validointilogiikan, rakensimme palautusmekanismin ja integroimme sen asiakkaan CI-putkeen. Tällä kertaa se sisälsi testit ja kuivakäyttötuen.
- Manuaalinen tietojen palauttaminen (6 tuntia) Joitakin tietueita ei voitu palauttaa varmuuskopioista. Haimme puuttuvat kentät ulkoisista järjestelmistä (heidän CRM- ja sähköpostipalvelun tarjoajan sovellusliittymistä) ja palautimme loput manuaalisesti.
Kokonaisaika: 30 tuntia
Kaksi insinööriä, kolme päivää. Kustannukset asiakkaalle: noin $4,500 palvelumaksut.
Suurempi isku tuli kuitenkin asiakkaiden aiheuttamista ongelmista. Epäonnistuneet ilmoitukset johtivat maksamatta jääneisiin maksuihin ja asiakaspoistumisiin. Asiakas kertoi käyttäneensä ainakin $10,000 tukipyynnöistä, SLA-kompensaatioista ja hyväntahtoisuushyvityksistä, jotka johtuvat yhdestä epäonnistuneesta käsikirjoituksesta.
Ironista on se, että vanhempi kehittäjä olisi voinut kirjoittaa oikean migraation ehkä neljässä tunnissa. Mutta lupaus AI-nopeudesta maksoi heille lopulta kaksi viikkoa siivousta ja maineen vahingoittumista.

 Rekrytoi
Rekrytoi