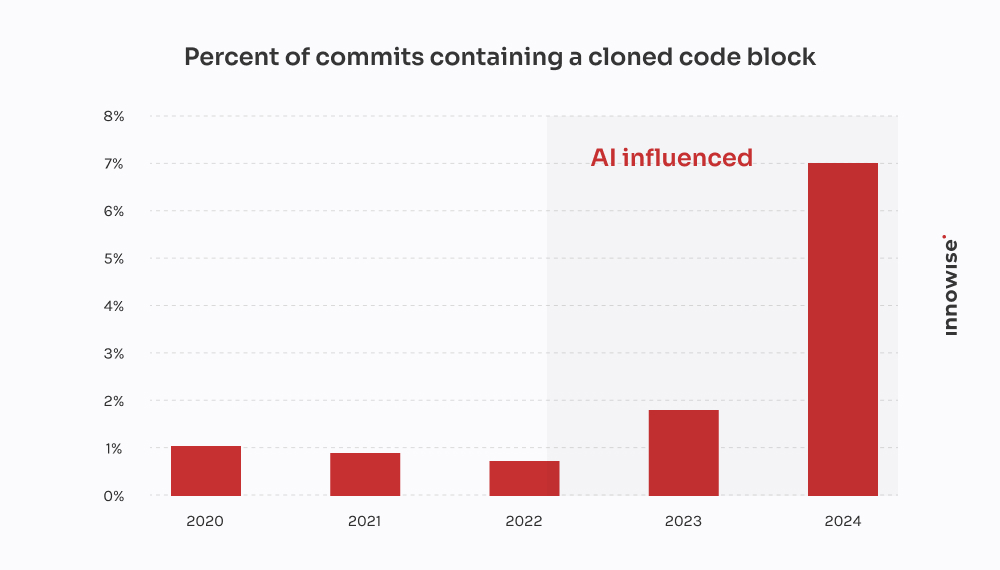
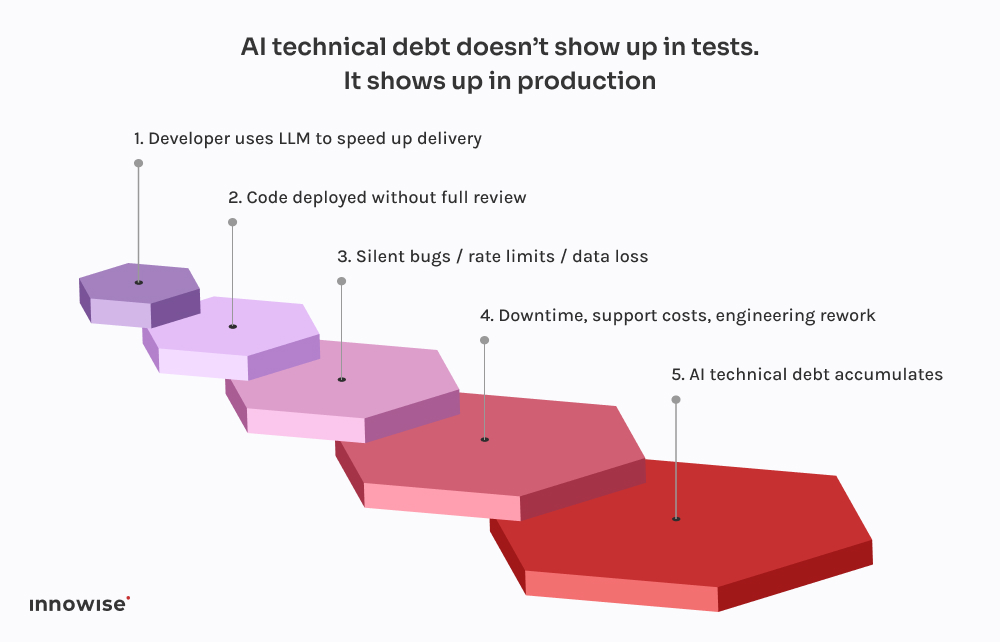
Vi er her ikke for at fortælle dig, at du skal forbyde AI-værktøjer. Det skib er sejlet.
Men at give en sprogmodel commit-adgang? Det er bare at bede om problemer.
Her er, hvad vi anbefaler i stedet:
1. Behandl LLM'er som værktøjer, ikke som ingeniører
Lad dem hjælpe med gentagen kode. Lad dem foreslå løsninger. Men Stol ikke på dem med kritiske beslutninger. Enhver kode, der genereres af AI, skal gennemgås af en senioringeniør, ingen undtagelser.
2. Gør LLM-genereret kode sporbar
Uanset om det er commit-tags, metadata eller kommentarer i koden, gør det klart, hvilke dele der kom fra AI. Det gør det lettere at revidere, fejlfinde og forstå risikoprofilen senere.
3. Definér en generationspolitik
Beslut som et team, hvor det er acceptabelt at bruge LLM'er, og hvor det ikke er. Standardtekst? Selvfølgelig. Auth-flow? Ja, måske. Transaktionelle systemer? Absolut ikke uden gennemgang. Gør politikken eksplicit og en del af dine tekniske standarder.
4. Tilføj overvågning på DevOps-niveau
Hvis du lader AI-genereret kode komme i kontakt med produktionen, er du nødt til at antage, at noget vil gå i stykker på et tidspunkt. Tilføj syntetiske kontroller. Overvågning af hastighedsbegrænsning. Sporing af afhængigheder. Gør det usynlige synligt, især når den oprindelige forfatter ikke er et menneske.
5. Byg med henblik på genoprettelse
De største AI-drevne fejl, vi har set, kom ikke fra "dårlig" kode. De kom fra stille fejl - manglende data, ødelagte køer, genforsøgsstorme - som ikke blev opdaget i timevis. Invester i observerbarhed, fallback-logik og rollbacks. Især hvis du lader ChatGPT skrive migreringer.
Kort sagt kan AI spare dit team for tid, men den kan ikke tage ansvar.
Det er stadig et menneskeligt job.

 Ansæt
Ansæt